
Automatisk talegjenkjenning (ASR) har kommet langt. Selv om det ble oppfunnet for lenge siden, ble det nesten aldri brukt av noen. Imidlertid har tid og teknologi nå endret seg betydelig. Lydtranskripsjon har utviklet seg betydelig.
Teknologier som AI (Artificial Intelligence) har drevet prosessen med lyd-til-tekst-oversettelse for raske og nøyaktige resultater. Som et resultat har applikasjonene i den virkelige verden også økt, med noen populære apper som Tik Tok, Spotify og Zoom som har innebygd prosessen i mobilappene deres.
Så la oss utforske ASR og oppdage hvorfor det er en av de mest populære teknologiene i 2022.
Hva er tale til tekst?
Tale til tekst er en AI-forbedret teknologi som oversetter menneskelig tale fra en analog til en digital form. Videre blir den digitale formen til de innsamlede dataene transkribert til et tekstformat.
Tale til tekst forveksles ofte med stemmegjenkjenning som er helt forskjellig fra denne metoden. I stemmegjenkjenning er fokuset på å identifisere stemmemønstrene til mennesker, mens i denne metoden prøver systemet å identifisere ordene som blir sagt.
Vanlige navn på tale til tekst
Denne avanserte talegjenkjenningsteknologien er også populær og referert til med navnene:
- Automatisk talegjenkjenning (ASR)
- Talegjenkjenning
- Datamaskin talegjenkjenning
- Lydtranskripsjon
- Skjermlesing
Forstå hvordan automatisk talegjenkjenning fungerer
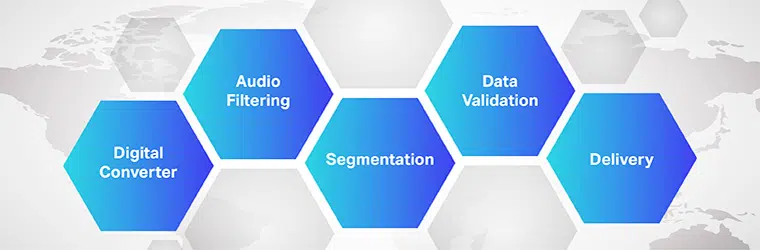
Arbeidet med lyd-til-tekst-oversettelsesprogramvare er komplekst og involverer implementering av flere trinn. Som vi vet er tale-til-tekst en eksklusiv programvare utviklet for å konvertere lydfiler til et redigerbart tekstformat; det gjør det ved å utnytte stemmegjenkjenning.
Prosess
- Ved å bruke en analog-til-digital-omformer bruker et dataprogram til å begynne med språklige algoritmer på de oppgitte dataene for å skille vibrasjoner fra auditive signaler.
- Deretter filtreres de relevante lydene ved å måle lydbølgene.
- Videre er lydene fordelt/segmentert i hundredeler eller tusendeler av sekunder og matchet mot fonemer (En målbar enhet av lyd for å skille ett ord fra et annet).
- Fonemene kjøres videre gjennom en matematisk modell for å sammenligne eksisterende data med velkjente ord, setninger og uttrykk.
- Utgangen er i en tekst- eller datamaskinbasert lydfil.
[Les også: En omfattende oversikt over automatisk talegjenkjenning]

Hva er bruken av tale til tekst?
Det er flere bruksområder for automatisk talegjenkjenning, som f.eks
- Innholdssøk: De fleste av oss har gått fra å skrive bokstaver på telefonene våre til å trykke på en knapp for at programvaren skal gjenkjenne stemmen vår og gi de ønskede resultatene.
- Kundeservice: Chatbots og AI-assistenter som kan veilede kundene gjennom de få innledende trinnene i prosessen er blitt vanlig.
- Teksting i sanntid: Med økt global tilgang til innhold, har teksting i sanntid blitt et fremtredende og betydningsfullt marked, noe som driver ASR fremover for bruk.
- Elektronisk dokumentasjon: Flere administrasjonsavdelinger har begynt å bruke ASR for å oppfylle dokumentasjonsformål, for bedre hastighet og effektivitet.
Hva er de viktigste utfordringene for talegjenkjenning?
Lydkommentar har ennå ikke nådd toppen av sin utvikling. Det er fortsatt mange utfordringer som ingeniørene prøver å imøtegå for å gjøre systemet effektivt, som f.eks
- Få kontroll over aksenter og dialekter.
- Forstå konteksten til de talte setningene.
- Separasjon av bakgrunnsstøy for å forsterke inngangskvaliteten.
- Bytte koden til forskjellige språk for effektiv behandling.
- Analysere de visuelle signalene som brukes i talen når det gjelder videofiler.
Lydtranskripsjoner og tale-til-tekst AI-utvikling
Den største utfordringen med programvaren for automatisk talegjenkjenning er å lage utgangen 100 % nøyaktig. Siden rådataene er dynamiske og en enkelt algoritme ikke kan brukes, blir dataene kommentert for å trene AI til å forstå dem i riktig kontekst.
For å utføre denne prosessen må spesifikke oppgaver implementeres, for eksempel:
 Navngitt enhetsgjenkjenning (NER): NER er prosessen med å identifisere og segmentere forskjellige navngitte enheter i spesifikke kategorier.
Navngitt enhetsgjenkjenning (NER): NER er prosessen med å identifisere og segmentere forskjellige navngitte enheter i spesifikke kategorier.- Sentiment og emneanalyse: Programvaren som bruker flere algoritmer, utfører sentimentanalysen av de oppgitte dataene for å gi feilfrie resultater.
 Navngitt enhetsgjenkjenning (NER):
Navngitt enhetsgjenkjenning (NER): - Intensjons- og samtaleanalyse: Intensjonsdeteksjon har som mål å trene AI til å gjenkjenne høyttalerens intensjon. Den brukes hovedsakelig til å lage AI-drevne chatbots.
konklusjonen
Tale-til-tekst-teknologi er på et flott stadium for øyeblikket. Med flere digitale enheter som inkluderer stemmesøk og kontrollassistenter i appene sine, vil etterspørselen etter lydtranskripsjon øke. Hvis du er opptatt av å legge til denne imponerende funksjonen i appen din, kan du kontakte Shaips eksperter for innsamling av taledata for å få alle detaljene.


