
Bilde sier tusen ord er et ganske vanlig ordtak vi alle har hørt. Nå, hvis et bilde kan si mer enn tusen ord, tenk deg hva en video kan si? En million ting, kanskje. Et av de revolusjonerende underfeltene innen kunstig intelligens er datalæring. Ingen av de banebrytende applikasjonene vi har blitt lovet, for eksempel førerløse biler eller intelligente utsjekker, er mulig uten videokommentarer.
Kunstig intelligens brukes på tvers av flere bransjer for å automatisere komplekse prosjekter, utvikle innovative og avanserte produkter og levere verdifull innsikt som endrer virksomhetens natur. Datasyn er et slikt underfelt av AI som fullstendig kan endre måten flere bransjer som er avhengige av enorme mengder tatt bilder og videoer fungerer på.
Datasyn, også kalt CV, lar datamaskiner og relaterte systemer trekke meningsfulle data fra visuelle elementer – bilder og videoer, og iverksette nødvendige tiltak basert på denne informasjonen. Maskinlæringsmodeller er opplært til å gjenkjenne mønstre og fange denne informasjonen i deres kunstige lagring for å tolke sanntids visuelle data effektivt.


Hva er videokommentarer?
Videokommentarer er teknikken for å gjenkjenne, merke og merke hvert objekt i en video. Det hjelper maskiner og datamaskiner å gjenkjenne objekter i bevegelse fra bilde til bilde i en video.
 Med enkle ord gransker en menneskelig kommentator en video, merker bildet ramme-for-bilde og kompilerer det til forhåndsbestemte kategoridatasett, som brukes til å trene maskinlæringsalgoritmer. De visuelle dataene berikes ved å legge til tagger med viktig informasjon om hver videoramme.
Med enkle ord gransker en menneskelig kommentator en video, merker bildet ramme-for-bilde og kompilerer det til forhåndsbestemte kategoridatasett, som brukes til å trene maskinlæringsalgoritmer. De visuelle dataene berikes ved å legge til tagger med viktig informasjon om hver videoramme.
Ingeniører kompilerte de kommenterte bildene til datasett under forhåndsbestemt
kategorier for å trene sine nødvendige ML-modeller. Tenk deg at du trener en modell for å forbedre evnen til å forstå trafikksignaler. Det som i hovedsak skjer er at algoritmen er trent på grunnsannhetsdata som har enorme mengder videoer som viser trafikksignaler som hjelper ML-modellen til å forutsi trafikkreglene nøyaktig.
Formål med videomerking og merking i ML
Videoannotering brukes hovedsakelig for å lage et datasett for å utvikle en visuell persepsjonsbasert AI-modell. Kommenterte videoer er mye brukt til å bygge autonome kjøretøy som kan oppdage veiskilt, fotgjengeres tilstedeværelse, gjenkjenne kjørefeltgrenser og forhindre ulykker på grunn av uforutsigbar menneskelig atferd. Kommenterte videoer tjener spesifikke formål for detaljhandelen når det gjelder utsjekkingsfrie butikker og gir tilpassede produktanbefalinger.
Den brukes også i medisinske og helsefaglige felt, spesielt i medisinsk kunstig intelligens, for nøyaktig sykdomsidentifikasjon og assistanse under operasjoner. Forskere utnytter også denne teknologien for å studere effekten av solteknologi på fugler.
Videokommentarer har flere applikasjoner i den virkelige verden. Den brukes i mange bransjer, men bilindustrien utnytter hovedsakelig potensialet sitt til å utvikle autonome kjøretøysystemer. La oss ta en dypere titt på hovedformålet.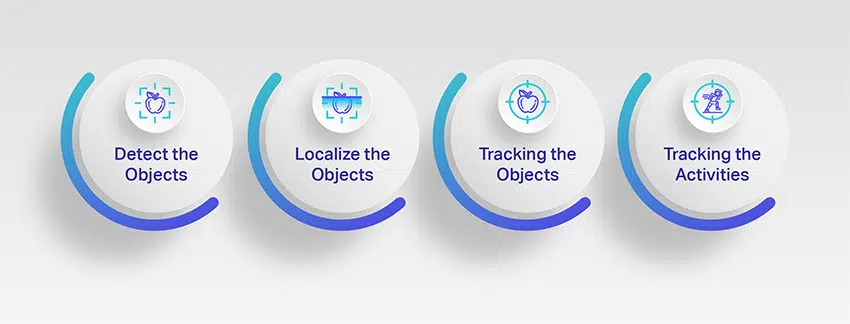
Oppdag objektene
Videokommentarer hjelper maskiner med å gjenkjenne objekter som er fanget i videoene. Siden maskiner ikke kan se eller tolke verden rundt dem, trenger de hjelp av mennesker for å identifisere målobjektene og gjenkjenne dem nøyaktig i flere rammer.
For at et maskinlæringssystem skal fungere feilfritt, må det trenes på enorme mengder data for å oppnå ønsket resultat
Lokaliser objektene
Det er mange objekter i en video, og å kommentere for hvert objekt er utfordrende og noen ganger unødvendig. Objektlokalisering betyr å lokalisere og kommentere det mest synlige objektet og den mest synlige delen av bildet.
Sporing av objektene
Videokommentarer brukes hovedsakelig til å bygge autonome kjøretøy, og det er avgjørende å ha et objektsporingssystem som hjelper maskiner til å forstå menneskelig atferd og veidynamikk nøyaktig. Den hjelper til med å spore trafikkflyten, fotgjengers bevegelser, kjørefelt, signaler, veiskilt og mer.
Sporing av aktivitetene
En annen grunn til at videoannotering er viktig, er at den er vant til trene datasyn-baserte ML-prosjekter for å estimere menneskelige aktiviteter og posere nøyaktig. Videokommentarer bidrar til å bedre forstå miljøet ved å spore menneskelig aktivitet og analysere uforutsigbar atferd. Dessuten bidrar dette også til å forhindre ulykker ved å overvåke aktivitetene til ikke-statiske objekter som fotgjengere, katter, hunder og mer og estimere deres bevegelser for å utvikle førerløse kjøretøy.
Videokommentar vs. bildekommentar
Video- og bildekommentarer er ganske like på mange måter, og teknikkene som brukes til å kommentere rammer, gjelder også for videokommentarer. Imidlertid er det noen få grunnleggende forskjeller mellom disse to, som vil hjelpe bedrifter med å bestemme riktig type datanotering de trenger for sitt spesifikke formål.

Teknikker for videokommentarer
Bilde- og videokommentarer bruker nesten lignende verktøy og teknikker, selv om det er mer komplekst og arbeidskrevende. I motsetning til et enkelt bilde, er en video vanskelig å kommentere siden den kan inneholde nesten 60 bilder per sekund. Videoer tar lengre tid å kommentere og krever også avanserte merknadsverktøy.
Enkeltbildemetode
 Enkeltbilde-videomerkingsmetoden er den tradisjonelle teknikken som trekker ut hver ramme fra videoen og merker rammene én etter én. Videoen er delt inn i flere rammer, og hvert bilde er kommentert ved hjelp av det tradisjonelle bildekommentar metoden. For eksempel er en video på 40 bilder per sekund delt opp i bilder på 2,400 per minutt.
Enkeltbilde-videomerkingsmetoden er den tradisjonelle teknikken som trekker ut hver ramme fra videoen og merker rammene én etter én. Videoen er delt inn i flere rammer, og hvert bilde er kommentert ved hjelp av det tradisjonelle bildekommentar metoden. For eksempel er en video på 40 bilder per sekund delt opp i bilder på 2,400 per minutt.
Enkeltbildemetoden ble brukt før annotatorverktøy ble tatt i bruk; Dette er imidlertid ikke en effektiv måte å kommentere video på. Denne metoden er tidkrevende og gir ikke fordelene en video tilbyr.
En annen stor ulempe med denne metoden er at siden hele videoen betraktes som en samling separate rammer, skaper den feil i objektidentifikasjon. Det samme objektet kan klassifiseres under forskjellige etiketter i forskjellige rammer, noe som gjør at hele prosessen mister nøyaktighet og kontekst.
Tiden som går med til å kommentere videoer ved hjelp av enkeltbildemetoden er eksepsjonelt høy, noe som øker kostnadene for prosjektet. Selv et mindre prosjekt på mindre enn 20 bilder per sekund vil ta lang tid å kommentere. Det kan være mange feilklassifiseringsfeil, tapte tidsfrister og merknadsfeil.
Kontinuerlig rammemetode
 Metoden for kontinuerlig ramme eller streamingramme er den mest populære. Denne metoden bruker merknadsverktøy som sporer objektene gjennom hele videoen med deres plassering bilde for bilde. Ved å bruke denne metoden opprettholdes kontinuiteten og konteksten godt.
Metoden for kontinuerlig ramme eller streamingramme er den mest populære. Denne metoden bruker merknadsverktøy som sporer objektene gjennom hele videoen med deres plassering bilde for bilde. Ved å bruke denne metoden opprettholdes kontinuiteten og konteksten godt.
Kontinuerlig frame-metoden bruker teknikker som optisk flyt for å fange opp pikslene i ett bilde og det neste nøyaktig og analysere bevegelsen til pikslene i det gjeldende bildet. Det sikrer også at objekter blir klassifisert og merket konsekvent på tvers av videoen. Enheten gjenkjennes konsekvent selv når den beveger seg inn og ut av rammen.
Når denne metoden brukes til å kommentere videoer, kan maskinlæringsprosjektet nøyaktig identifisere objekter som er tilstede i begynnelsen av videoen, forsvinne ut av syne i noen få bilder og dukke opp igjen.
Hvis en enkeltbildemetode brukes for merknader, kan datamaskinen vurdere det gjenopptatte bildet som et nytt objekt, noe som resulterer i feilklassifisering. Men i en kontinuerlig rammemetode vurderer datamaskinen bevegelsen til bildene, og sikrer at kontinuiteten og integriteten til videoen opprettholdes godt.
Den kontinuerlige rammemetoden er en raskere måte å kommentere på, og den gir større muligheter til ML-prosjekter. Kommentaren er presis, eliminerer menneskelig skjevhet, og kategoriseringen er mer nøyaktig. Det er imidlertid ikke uten risiko. Noen faktorer som kan endre effektiviteten, for eksempel bildekvalitet og videooppløsning.






Vanlige utfordringer ved videokommentarer
Videokommentarer/-merking kan utgjøre noen utfordringer for kommentatorer. La oss se på noen punkter du må vurdere før du begynner videokommentar for datasyn prosjekter.
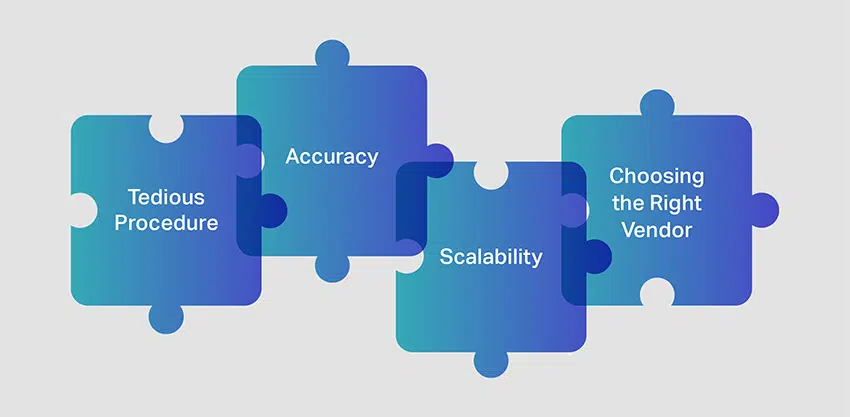
Kjedelig prosedyre
En av de største utfordringene med videokommentarer er å håndtere massive videodatasett som må granskes og kommenteres. For å trene datasynsmodellene nøyaktig, er det avgjørende å få tilgang til store mengder kommenterte videoer. Siden objektene ikke er stille, slik de ville vært i en bildekommentarprosess, er det viktig å ha svært dyktige annotatorer som kan fange objekter i bevegelse.
Videoene må brytes ned i mindre klipp med flere rammer, og individuelle objekter kan deretter identifiseres for nøyaktig merknad. Med mindre det brukes annoteringsverktøy, er det en risiko for at hele annoteringsprosessen blir kjedelig og tidkrevende.
Nøyaktighet
Å opprettholde et høyt nivå av nøyaktighet under videokommentarprosessen er en utfordrende oppgave. Merknadskvaliteten bør kontrolleres konsekvent på hvert trinn for å sikre at objektet spores, klassifiseres og merkes riktig.
Med mindre kvaliteten på merknadene ikke kontrolleres på forskjellige nivåer, er det umulig å designe eller trene en unik og kvalitetsalgoritme. Dessuten kan unøyaktig kategorisering eller annotering også alvorlig påvirke kvaliteten på prediksjonsmodellen.
skalerbarhet
I tillegg til å sikre nøyaktighet og presisjon, bør videokommentarer også være skalerbare. Bedrifter foretrekker merknadstjenester som hjelper dem raskt å utvikle, distribuere og skalere ML-prosjekter uten å ha stor innvirkning på bunnlinjen.
Velge riktig videomerkingsleverandør
 Den siste og sannsynligvis mest avgjørende utfordringen innen videokommentarer er å engasjere tjenestene til en pålitelig og erfaren leverandør av videodataannoteringstjenester. Å ha en ekspert tjenesteleverandør for videokommentarer vil gå langt i å sikre at ML-prosjektene dine er robust utviklet og distribuert i tide.
Den siste og sannsynligvis mest avgjørende utfordringen innen videokommentarer er å engasjere tjenestene til en pålitelig og erfaren leverandør av videodataannoteringstjenester. Å ha en ekspert tjenesteleverandør for videokommentarer vil gå langt i å sikre at ML-prosjektene dine er robust utviklet og distribuert i tide.
Det er også viktig å engasjere en leverandør som sikrer at sikkerhetsstandarder og forskrifter følges grundig. Å velge den mest populære leverandøren eller den billigste er kanskje ikke alltid det riktige trekket. Du bør søke den rette leverandøren basert på dine prosjektbehov, kvalitetsstandarder, erfaring og teamekspertise.