
Store språkmodeller har nylig fått massiv fremtreden etter at deres svært kompetente brukscase ChatGPT ble en suksess over natten. Etter å ha sett suksessen til ChatGPT og andre ChatBots, har en mengde mennesker og organisasjoner blitt interessert i å utforske teknologien som driver slik programvare.
Store språkmodeller er ryggraden bak denne programvaren som gjør det mulig å arbeide med ulike Natural Language Processing-applikasjoner som maskinoversettelse, talegjenkjenning, svar på spørsmål og tekstoppsummering. La oss lære mer om LLM og hvordan du kan optimalisere det for de beste resultatene.
Hva er store språkmodeller eller ChatGPT?
Store språkmodeller er maskinlæringsmodeller som utnytter kunstige nevrale nettverk og store siloer med data for å drive NLP-applikasjoner. Ved å trene på store datamengder, får LLM evnen til å fange opp ulike kompleksiteter av naturlig språk, som det videre utnyttet til:
- Generering av ny tekst
- Oppsummering av artikler og passasjer
- Uttrekk av data
- Omskriving eller parafrasering av teksten
- Klassifisering av data
Noen populære eksempler på LLM er BERT, Chat GPT-3 og XLNet. Disse modellene er trent på hundrevis av millioner av tekster og kan gi verdifulle løsninger på alle typer distinkte brukerforespørsler.
Populære brukstilfeller av store språkmodeller
Her er noen av de beste og mest utbredte brukstilfellene av LLM:
Tekstgenerering
Store språkmodeller bruker kunstig intelligens og datalingvistikkkunnskap for automatisk å generere naturlige språktekster og fullføre ulike kommunikative brukerkrav som å skrive artikler, sanger eller til og med chatte med brukerne.
Maskinoversettelse
LLM-er kan også brukes til å oversette tekst mellom to forskjellige språk. Modellene utnytter dyplæringsalgoritmer, for eksempel tilbakevendende nevrale nettverk, for å lære språkstrukturen til kilde- og målspråkene. Følgelig brukes de til å oversette kildetekst til målspråket.
Content Creation
LLM-er har nå gjort det mulig for maskiner å lage sammenhengende og logisk innhold som kan brukes til å generere blogginnlegg, artikler og andre former for innhold. Modellene bruker sin omfattende dyplæringskunnskap til å forstå og strukturere innholdet i et unikt og lesbart format for brukerne.
Sentiment Analyse
Det er et spennende bruksområde for store språkmodeller der modellen er opplært til å identifisere og klassifisere emosjonelle tilstander og følelser i merket tekst. Programvaren kan oppdage følelser som positivitet, negativitet, nøytralitet og andre komplekse følelser som kan bidra til å få innsikt i kundenes meninger og anmeldelser om forskjellige produkter og tjenester.
Forståelse, oppsummering og klassifisering av tekst
LLM-er gir et praktisk rammeverk for AI-programvaren for å forstå teksten og dens kontekst. Ved å trene modellen til å forstå og analysere store hauger med data, gjør LLM det mulig for AI-modeller å forstå, oppsummere og til og med klassifisere tekst i forskjellige former og mønstre.
Spørsmål svar
Store språkmodeller gjør det mulig for QA-systemer å nøyaktig oppdage og svare på en brukers naturlige språkspørring. En av de mest populære applikasjonene for denne brukssaken er ChatGPT og BERT, som analyserer konteksten til en spørring og søker gjennom et stort korpus av tekster for å finne relevante svar på brukerforespørsler.
[ Les også: Fremtiden for språkbehandling: Store språkmodeller og eksempler ]

3 essensielle betingelser for å gjøre LLM-er vellykket
Følgende tre betingelser må være nøyaktig oppfylt for å øke effektiviteten og gjøre dine store språkmodeller vellykkede:
Tilstedeværelse av enorme mengder data for modelltrening
LLM trenger store mengder data for å trene opp modeller som gir effektive og optimale resultater. Det er spesifikke metoder, som overføringslæring og selvovervåket forhåndstrening, som LLM-ene utnytter for å forbedre ytelsen og nøyaktigheten.
Bygge lag av nevroner for å lette komplekse mønstre til modellene
En stor språkmodell må omfatte forskjellige lag med nevroner som er spesielt trent til å forstå de intrikate mønstrene i data. Nevroner i dypere lag kan bedre forstå komplekse mønstre enn grunnere lag. Modellen kan lære sammenhengen mellom ord, temaene som vises sammen, og forholdet mellom deler av tale.
Optimalisering av LLM-er for brukerspesifikke oppgaver
LLM-er kan tilpasses for spesifikke oppgaver ved å endre antall lag, nevroner og aktiveringsfunksjoner. For eksempel bruker en modell som forutsier følgende ord i setningen vanligvis færre lag og nevroner enn en modell designet for å generere nye setninger fra bunnen av.
Populære eksempler på store språkmodeller
Her er noen fremtredende eksempler på LLM-er som brukes mye i forskjellige industrivertikaler:
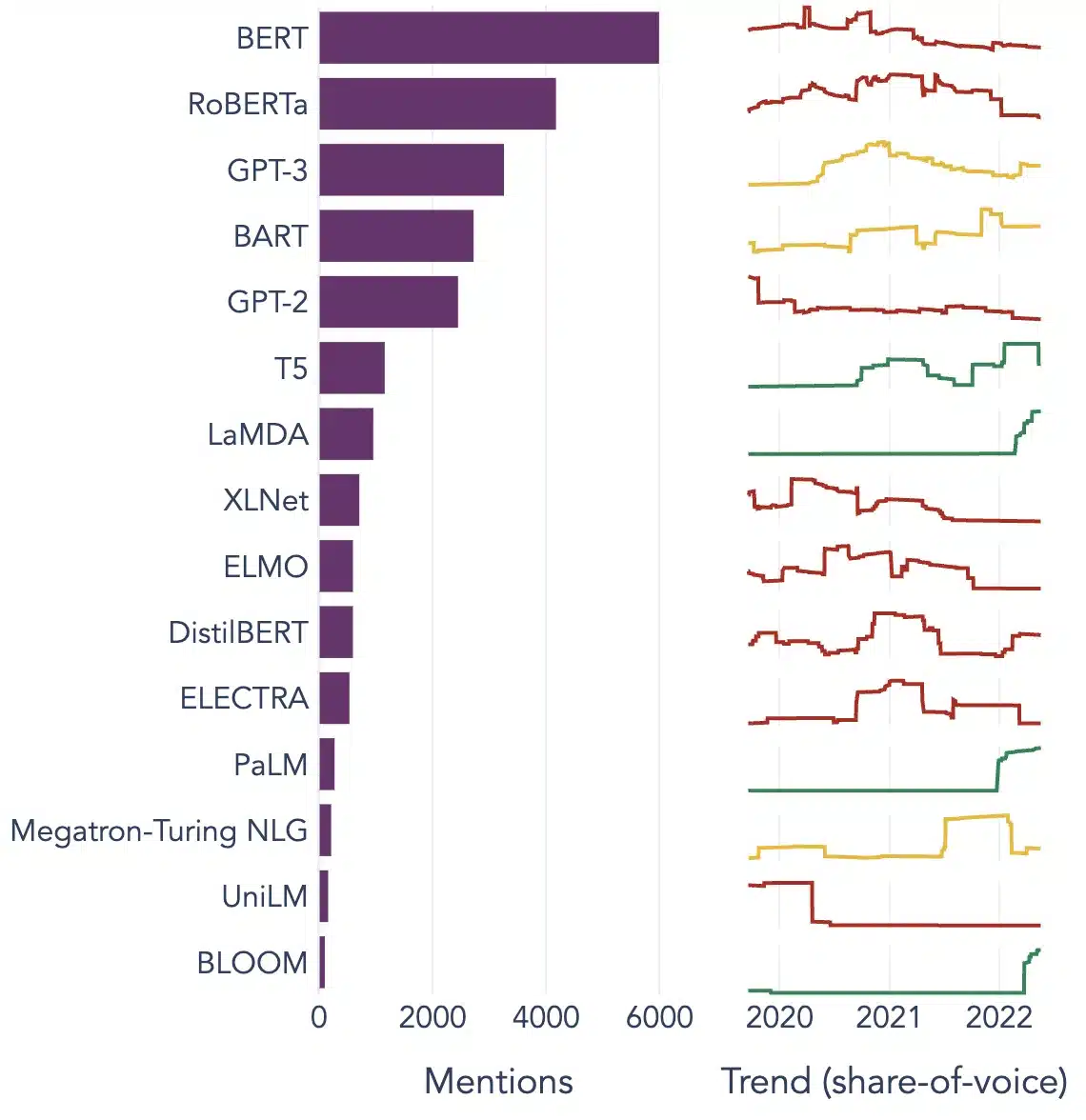
Image Source: Mot datavitenskap
konklusjonen
LLM-er ser potensialet til å revolusjonere NLP ved å tilby robuste og nøyaktige språkforståelsesevner og løsninger som gir en sømløs brukeropplevelse. Men for å gjøre LLM-er mer effektive, må utviklere utnytte høykvalitets taledata for å generere mer nøyaktige resultater og produsere svært effektive AI-modeller.
Shaip er en av de ledende AI-teknologiske løsningene som tilbyr et bredt spekter av taledata på over 50 språk og flere formater. Lær mer om LLM og få veiledning om prosjektene dine fra Shaip-eksperter i dag.


