
Fordeler med OCR
Optisk tegngjenkjenning – OCR-teknologi – gir en rekke fordeler, hvorav noen er:
Øk hastigheten på prosessen:
Ved å raskt konvertere ustrukturerte data til maskinlesbar og søkbar informasjon, hjelper teknologien med å øke hastigheten på forretningsprosesser.
Øker nøyaktigheten:
Risikoen for menneskelige feil er eliminert, noe som forbedrer den generelle nøyaktigheten av karaktergjenkjenningen.
Reduserer behandlingskostnadene:
Programvaren for optisk tegngjenkjenning er ikke helt avhengig av andre teknologier, noe som reduserer prosesseringskostnadene.
Forbedrer produktiviteten:
Siden informasjon er lett tilgjengelig og søkbar, har ansatte mer tid til å utføre produktive oppgaver og nå mål.
Forbedrer kundetilfredsheten:
Tilgjengeligheten av informasjon i et lett søkbart format sikrer høyere tilfredshetsnivåer og en bedre kundeopplevelse.
Brukssaker og applikasjoner
Bevaring av dokumenter / Digitalisering av dokumenter
 Gamle historiske dokumenter av verdi kan bevares, lagres og gjøres uforgjengelige ved å konvertere dem til digitalisert format. OCR-teknologi brukes til å digitalisere antikke og sjeldne bøker, så disse manuskriptene med uregelmessige skrifttyper kan endres digitalt og gjøres søkbare for fremtiden.
Gamle historiske dokumenter av verdi kan bevares, lagres og gjøres uforgjengelige ved å konvertere dem til digitalisert format. OCR-teknologi brukes til å digitalisere antikke og sjeldne bøker, så disse manuskriptene med uregelmessige skrifttyper kan endres digitalt og gjøres søkbare for fremtiden.
Bank og finans
Bank- og finanssektoren bruker OCT-teknologien til sitt. Denne teknologien bidrar til å forbedre forebygging av sikkerhetssvindel, redusere risiko og raskere behandling. Banker og bankapper bruker OCR for å trekke ut viktige data fra sjekker som kontonummer, beløp og håndsignatur. OCR hjelper til med raskere behandling av låne- og boliglånssøknader, fakturaer og lønnsslipper.
Før OCR ble mer vanlig, var alle bankdokumenter som poster, kvitteringer, kontoutskrifter og sjekker fysiske. Med OCR-digitalisering kan banker og finansinstitusjoner strømlinjeforme prosesser, eliminere manuelle feil og forbedre prosesseffektiviteten ved å raskt få tilgang til data.
Nummerskiltgjenkjenning
 OCR-teknologien er mye brukt for å identifisere numre og tekst på nummerskilt. Denne teknologien brukes til å identifisere tapte biler, beregning av parkeringsavgifter og forebygge kjøretøykriminalitet.
OCR-teknologien er mye brukt for å identifisere numre og tekst på nummerskilt. Denne teknologien brukes til å identifisere tapte biler, beregning av parkeringsavgifter og forebygge kjøretøykriminalitet.
OCR-teknologi hjelper til med å implementere trafikksikkerhetsregler for å unngå svindel og kriminalitet. Siden nummerplatene på et kjøretøy er knyttet til førerens legitimasjon, er identifisering enklere.
Dessuten består nummerskiltene av en velskrevet haug med tall og tekst som ikke er vanskelig å lese for AI-modellen, noe som gjør det enklere og mer nøyaktig.
Tekst-til-tale
Tekst-til-tale-applikasjon av OCR-teknologi er en utmerket hjelp for visuelt utfordrede personer til å fungere med større letthet. OCR-teknologi hjelper til med å skanne fysiske og digitale tekster og bruke taleenheter. Innholdet leses deretter opp. Selv om tekst-til-tale-aspektet ved OCR-teknologi har vært en av de første applikasjonene, er den nå utviklet og avansert for å imøtekomme de unike behovene til visuelt utfordrede mennesker ved å støtte flere dialekter og språk.
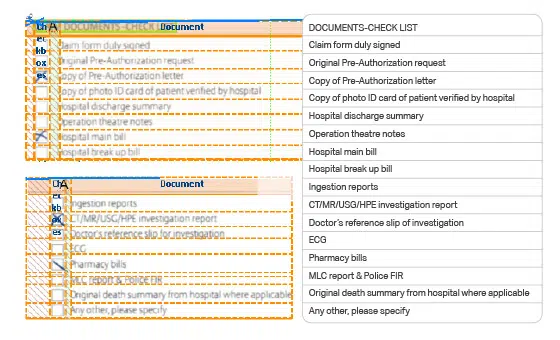
Transkripsjon av Multi-category Skannede papirdokumenter datasett
 Ved å bruke OCR-teknologi blir fakturaer, kvitteringer, regninger og andre dokumenter av forskjellige kategorier også transkribert effektivt. Nyhetsbrev, papirer med sirkler, avkrysningsboksskjemaer og dokumenter med flere kategorier som skatteskjemaer og manualer kan også digitaliseres.
Ved å bruke OCR-teknologi blir fakturaer, kvitteringer, regninger og andre dokumenter av forskjellige kategorier også transkribert effektivt. Nyhetsbrev, papirer med sirkler, avkrysningsboksskjemaer og dokumenter med flere kategorier som skatteskjemaer og manualer kan også digitaliseres.
Transkribere medisinske etiketter med OCR
 Ved å hjelpe med å skanne reseptbelagte medisinske etiketter ved hjelp av OCR, er det nå mulig å automatisk fange medisinske data. Det medisinske data fanges opp fra håndskrevne resepter, legemiddelinformasjon og mengde for å unngå manuelle feil, duplisering og uaktsomhet.
Ved å hjelpe med å skanne reseptbelagte medisinske etiketter ved hjelp av OCR, er det nå mulig å automatisk fange medisinske data. Det medisinske data fanges opp fra håndskrevne resepter, legemiddelinformasjon og mengde for å unngå manuelle feil, duplisering og uaktsomhet.
Med OCR kan helsesektoren raskt skanne, lagre og søke etter en pasients sykehistorie. OCR gjør det mulig å digitalisere og lagre skannerapporter, behandlingshistorikk, sykehusjournaler, forsikringsjournaler, røntgenbilder og andre dokumenter. Ved å digitalisere, transkribere og lagre medisinske etiketter gjør OCR det enkelt å strømlinjeforme prosessflyten og øke hastigheten på helsevesenet.
Oppdage gate/vei og trekke ut informasjon Street Board-data med OCR
 Automatisk gjenkjenning, identifikasjon og klassifisering av vei-/gateskilt gjøres med OCR. Ved å oppdage veiskilt, leder OCR sjåførene mot en tryggere reise. OCR-teknologien fungerer like godt under dårlige lysforhold, oppdager veiskilt på flere språk og skilt med forskjellig form, og klassifiserer det samme for fremtiden.
Automatisk gjenkjenning, identifikasjon og klassifisering av vei-/gateskilt gjøres med OCR. Ved å oppdage veiskilt, leder OCR sjåførene mot en tryggere reise. OCR-teknologien fungerer like godt under dårlige lysforhold, oppdager veiskilt på flere språk og skilt med forskjellig form, og klassifiserer det samme for fremtiden.
Å utvikle en intelligent karaktergjenkjenning verktøyet, må du trene det med det prosjektspesifikke datasettet.
Hos Shaip tilbyr vi et fullstendig tilpasset dokumentdatasett for å utvikle svært funksjonelt OCR for AI- og ML-modeller. Vår spesialiserte prosessen med OCR hjelper med å utvikle optimaliserte løsninger for kunder.
Vi tilbyr omfattende og pålitelige datasett som inneholder tusenvis av forskjellige utvunnede data fra skannede dokumenter. Ta kontakt med vår OCR-løsninger eksperter for å vite hvordan vi leverer skalerbare, rimelige og klientspesifikke datasett.


