
Introduksjon
Denne veiledningen vil være ekstremt nyttig for de kjøpere og beslutningstakere som begynner å vende tankene mot mutterne og skruene ved datainnhenting og dataimplementering både for nevrale nettverk og andre typer AI- og ML-operasjoner.

Denne artikkelen er fullstendig dedikert til å kaste lys over hva prosessen er, hvorfor den er uunngåelig, avgjørende
faktorer bedrifter bør vurdere når de nærmer seg datakommentarverktøy og mer. Så hvis du eier en bedrift, gjør deg klar for å bli opplyst, da denne guiden vil lede deg gjennom alt du trenger å vite om datakommentarer.
La oss komme i gang.
For de av dere som skumles gjennom artikkelen, her er noen raske takeaways du finner i guiden:
- Forstå hva datakommentar er
- Kjenn til de forskjellige typene datamerkingsprosesser
- Kjenn fordelene ved å implementere datakommentarprosessen
- Få klarhet i om du bør gå for intern datamerking eller få dem satt ut
- Innsikt i valg av riktig datakommentar også
Hva er maskinlæring?
 Vi har snakket om hvordan datakommentarer eller datamerking støtter maskinlæring og at den består av tagging eller identifisering av komponenter. Men når det gjelder dyp læring og maskinlæring i seg selv: det grunnleggende premisset for maskinlæring er at datasystemer og programmer kan forbedre resultatene sine på måter som ligner menneskelige kognitive prosesser, uten direkte menneskelig hjelp eller intervensjon, for å gi oss innsikt. De blir med andre ord selvlærende maskiner som, omtrent som et menneske, blir bedre i jobben sin med mer øvelse. Denne "praksisen" oppnås ved å analysere og tolke flere (og bedre) treningsdata.
Vi har snakket om hvordan datakommentarer eller datamerking støtter maskinlæring og at den består av tagging eller identifisering av komponenter. Men når det gjelder dyp læring og maskinlæring i seg selv: det grunnleggende premisset for maskinlæring er at datasystemer og programmer kan forbedre resultatene sine på måter som ligner menneskelige kognitive prosesser, uten direkte menneskelig hjelp eller intervensjon, for å gi oss innsikt. De blir med andre ord selvlærende maskiner som, omtrent som et menneske, blir bedre i jobben sin med mer øvelse. Denne "praksisen" oppnås ved å analysere og tolke flere (og bedre) treningsdata.
Hva er datakommentarer?
Dataannotering er prosessen med å tilskrive, merke eller merke data for å hjelpe maskinlæringsalgoritmer med å forstå og klassifisere informasjonen de behandler. Denne prosessen er avgjørende for å trene AI-modeller, slik at de kan forstå ulike datatyper nøyaktig, for eksempel bilder, lydfiler, videoopptak eller tekst.
Se for deg en selvkjørende bil som er avhengig av data fra datasyn, naturlig språkbehandling (NLP) og sensorer for å ta nøyaktige kjøreavgjørelser. For å hjelpe bilens AI-modell med å skille mellom hindringer som andre kjøretøy, fotgjengere, dyr eller veisperringer, må dataene den mottar merkes eller kommenteres.
I overvåket læring er datamerking spesielt avgjørende, ettersom jo mer merkede data som mates til modellen, jo raskere lærer den å fungere autonomt. Annoterte data lar AI-modeller distribueres i ulike applikasjoner som chatbots, talegjenkjenning og automatisering, noe som resulterer i optimal ytelse og pålitelige resultater.
Hva er et datamerkings-/kommentarverktøy?
 Enkelt sagt er det en plattform eller en portal som lar spesialister og eksperter kommentere, merke eller merke datasett av alle typer. Det er en bro eller et medium mellom rådata og resultatene dine maskinlæringsmoduler til slutt vil gi.
Enkelt sagt er det en plattform eller en portal som lar spesialister og eksperter kommentere, merke eller merke datasett av alle typer. Det er en bro eller et medium mellom rådata og resultatene dine maskinlæringsmoduler til slutt vil gi.
Et datamerkingsverktøy er en lokal eller skybasert løsning som kommenterer opplæringsdata av høy kvalitet for maskinlæringsmodeller. Mens mange selskaper er avhengige av en ekstern leverandør for å gjøre komplekse merknader, har noen organisasjoner fortsatt sine egne verktøy som enten er spesialbygde eller er basert på freeware eller opensource-verktøy tilgjengelig i markedet. Slike verktøy er vanligvis utformet for å håndtere spesifikke datatyper, f.eks. bilde, video, tekst, lyd, osv. Verktøyene tilbyr funksjoner eller alternativer som avgrensende bokser eller polygoner for dataannotatorer for å merke bilder. De kan bare velge alternativet og utføre sine spesifikke oppgaver.
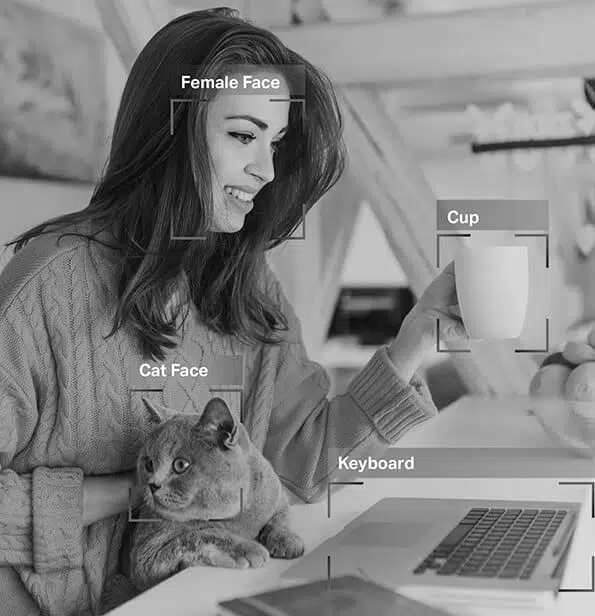
Bildekommentar

Fra datasettene de har blitt trent på, kan de umiddelbart og presist skille øynene dine fra nesen og øyenbrynet fra øyevippene. Det er derfor filtrene du bruker passer perfekt uavhengig av ansiktsformen, hvor nært du er kameraet og mer.
Så, som du nå vet, bildekommentar er viktig i moduler som involverer ansiktsgjenkjenning, datasyn, robotsyn og mer. Når AI-eksperter trener slike modeller, legger de til bildetekster, identifikatorer og nøkkelord som attributter til bildene deres. Algoritmene identifiserer og forstår deretter fra disse parameterne og lærer autonomt.
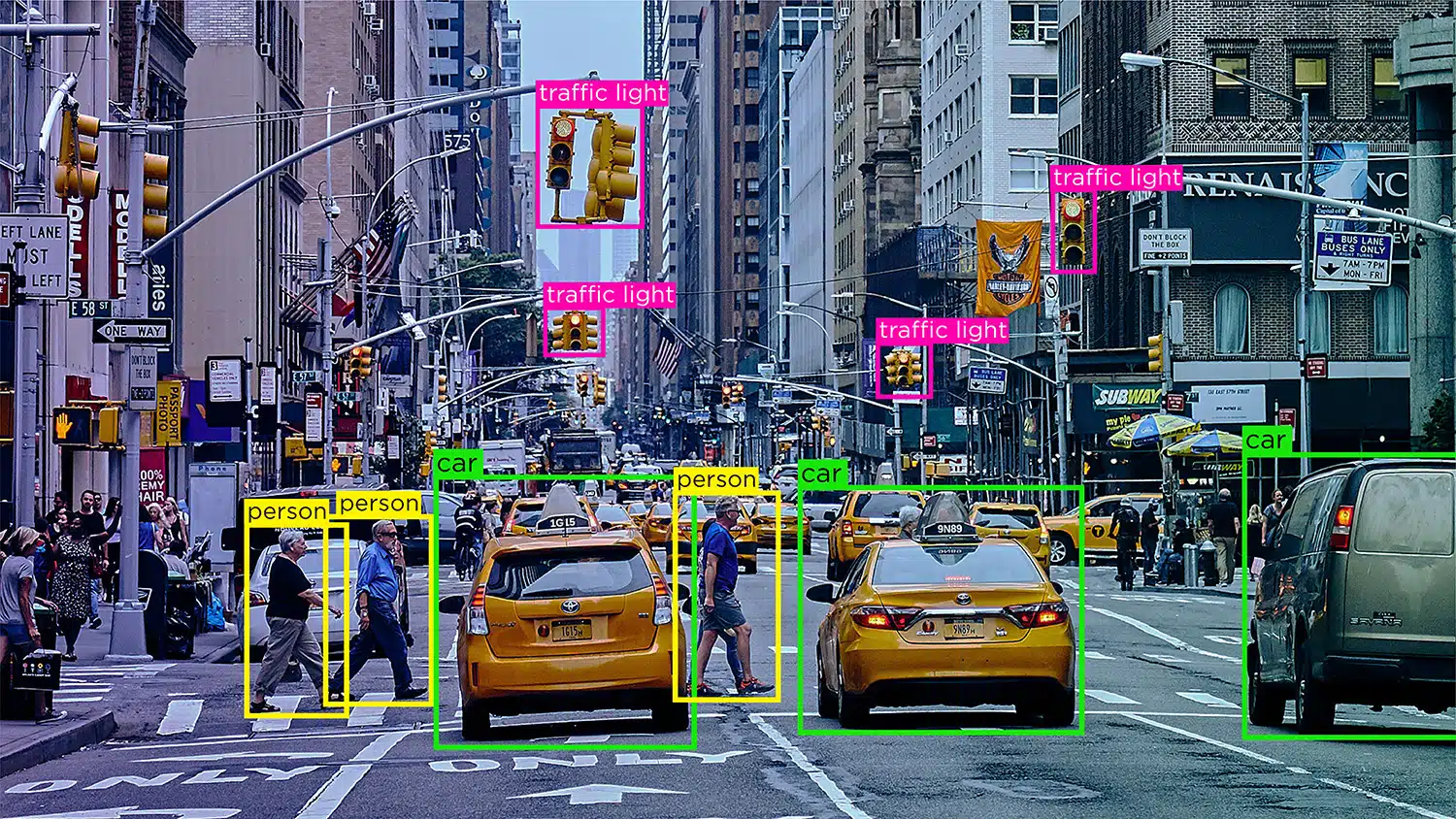
Bildeklassifisering – Bildeklassifisering innebærer å tilordne forhåndsdefinerte kategorier eller etiketter til bilder basert på innholdet. Denne typen merknader brukes til å trene AI-modeller til å gjenkjenne og kategorisere bilder automatisk.
Objektgjenkjenning/deteksjon – Objektgjenkjenning, eller objektdeteksjon, er prosessen med å identifisere og merke spesifikke objekter i et bilde. Denne typen merknader brukes til å trene AI-modeller til å finne og gjenkjenne objekter i virkelige bilder eller videoer.
segmentering – Bildesegmentering innebærer å dele et bilde inn i flere segmenter eller regioner, som hver tilsvarer et spesifikt objekt eller område av interesse. Denne typen merknader brukes til å trene AI-modeller til å analysere bilder på pikselnivå, noe som muliggjør mer nøyaktig objektgjenkjenning og sceneforståelse.
Lydkommentar
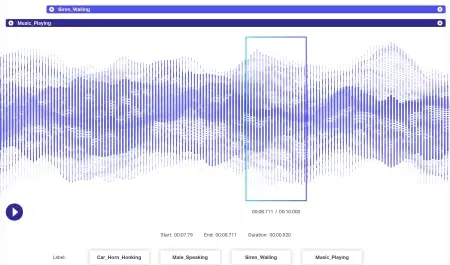
Lyddata har enda mer dynamikk knyttet til seg enn bildedata. Flere faktorer er assosiert med en lydfil, inkludert, men definitivt ikke begrenset til – språk, høyttalerdemografi, dialekter, humør, hensikt, følelser, atferd. For at algoritmer skal være effektive i behandlingen, bør alle disse parameterne identifiseres og merkes med teknikker som tidsstempling, lydmerking og mer. Foruten bare verbale signaler, kan ikke-verbale forekomster som stillhet, pust, til og med bakgrunnsstøy kommenteres slik at systemene kan forstå dem fullstendig.
Videokommentar

Mens et bilde er stille, er en video en samling av bilder som skaper en effekt av at objekter er i bevegelse. Nå kalles hvert bilde i denne samlingen en ramme. Når det gjelder videokommentarer, innebærer prosessen å legge til nøkkelpunkter, polygoner eller avgrensningsbokser for å kommentere forskjellige objekter i feltet i hver ramme.
Når disse rammene er sydd sammen, kan bevegelsen, oppførselen, mønstrene og mer læres av AI-modellene i aksjon. Det er bare gjennom videoannotering at konsepter som lokalisering, bevegelsesuskarphet og objektsporing kan implementeres i systemer.
Tekstkommentar

I dag er de fleste virksomheter avhengige av tekstbaserte data for unik innsikt og informasjon. Nå kan tekst være alt fra tilbakemeldinger fra kunder på en app til omtale i sosiale medier. Og i motsetning til bilder og videoer som for det meste formidler intensjoner som er rett frem, kommer tekst med mye semantikk.
Som mennesker er vi innstilt på å forstå konteksten til en setning, betydningen av hvert ord, setning eller setning, relatere dem til en bestemt situasjon eller samtale og deretter innse den helhetlige betydningen bak et utsagn. Maskiner, derimot, kan ikke gjøre dette på nøyaktige nivåer. Begreper som sarkasme, humor og andre abstrakte elementer er ukjente for dem, og det er derfor tekstdatamerking blir vanskeligere. Det er derfor tekstkommentarer har noen mer raffinerte stadier som følgende:
Semantisk kommentar – objekter, produkter og tjenester gjøres mer relevante ved hjelp av passende nøkkelsetningsmerking og identifikasjonsparametere. Chatbots er også laget for å etterligne menneskelige samtaler på denne måten.
Hensiktskommentar – intensjonen til en bruker og språket som brukes av dem er merket for maskiner å forstå. Med dette kan modeller skille en forespørsel fra en kommando, eller anbefaling fra en bestilling, og så videre.
Sentimentkommentar – Sentimentkommentarer innebærer å merke tekstdata med følelsen den formidler, for eksempel positiv, negativ eller nøytral. Denne typen merknader brukes ofte i sentimentanalyse, der AI-modeller er opplært til å forstå og evaluere følelsene som uttrykkes i tekst.

Enhetsmerknad – hvor ustrukturerte setninger er tagget for å gjøre dem mer meningsfulle og bringe dem til et format som kan forstås av maskiner. For å få dette til er to aspekter involvert – kalt enhet anerkjennelse og enhetskobling. Anerkjennelse av navngitte enheter er når navn på steder, personer, hendelser, organisasjoner og mer er merket og identifisert, og enhetskobling er når disse kodene er koblet til setninger, setninger, fakta eller meninger som følger dem. Til sammen etablerer disse to prosessene forholdet mellom tekstene knyttet og utsagnet rundt det.
Tekstkategorisering – Setninger eller avsnitt kan merkes og klassifiseres basert på overordnede emner, trender, emner, meninger, kategorier (sport, underholdning og lignende) og andre parametere.
Nøkkeltrinn i datamerkings- og datamerkingsprosessen
Datamerkingsprosessen involverer en rekke veldefinerte trinn for å sikre høykvalitets og nøyaktig datamerking for maskinlæringsapplikasjoner. Disse trinnene dekker alle aspekter av prosessen, fra datainnsamling til eksport av kommenterte data for videre bruk.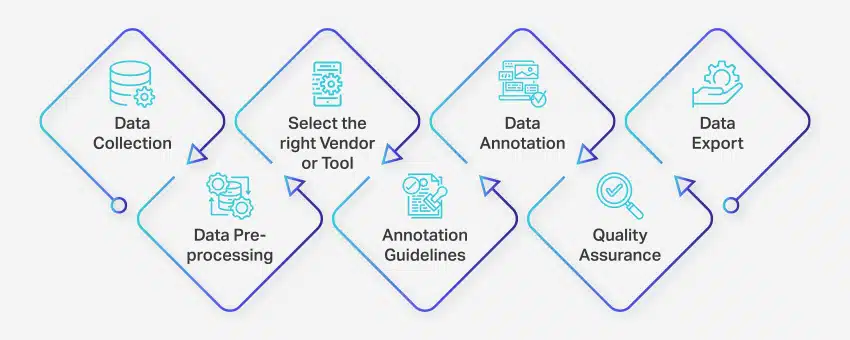
Slik foregår dataannotering:
- Datainnsamling: Det første trinnet i datakommentarprosessen er å samle alle relevante data, for eksempel bilder, videoer, lydopptak eller tekstdata, på et sentralisert sted.
- Dataforbehandling: Standardiser og forbedre de innsamlede dataene ved å rette opp bilder, formatere tekst eller transkribere videoinnhold. Forbehandling sikrer at dataene er klare for merknader.
- Velg riktig leverandør eller verktøy: Velg et passende datakommentarverktøy eller leverandør basert på prosjektets krav. Alternativer inkluderer plattformer som Nanonets for datakommentarer, V7 for bildekommentarer, Appen for videokommentarer og Nanonets for dokumentkommentarer.
- Retningslinjer for kommentarer: Etabler klare retningslinjer for kommentatorer eller merknadsverktøy for å sikre konsistens og nøyaktighet gjennom hele prosessen.
- merknad: Merk og merk dataene ved hjelp av menneskelige annotatorer eller datakommentarprogramvare, i henhold til de etablerte retningslinjene.
- Kvalitetssikring (QA): Se gjennom de kommenterte dataene for å sikre nøyaktighet og konsistens. Bruk flere blinde merknader, om nødvendig, for å verifisere kvaliteten på resultatene.
- Dataeksport: Etter å ha fullført datakommentaren, eksporter dataene i det nødvendige formatet. Plattformer som Nanonets muliggjør sømløs dataeksport til ulike forretningsapplikasjoner.
Hele datakommentarprosessen kan variere fra noen få dager til flere uker, avhengig av prosjektets størrelse, kompleksitet og tilgjengelige ressurser.
Funksjoner for verktøy for datamerking og datamerking
Dataannoteringsverktøy er avgjørende faktorer som kan gjøre eller ødelegge AI-prosjektet ditt. Når det kommer til presise utdata og resultater, spiller kvaliteten på datasett alene ingen rolle. Faktisk påvirker datakommentarverktøyene du bruker for å trene AI-modulene dine utdataene dine enormt.
Det er derfor det er viktig å velge og bruke det mest funksjonelle og hensiktsmessige datamerkingsverktøyet som dekker bedriftens eller prosjektets behov. Men hva er et dataannoteringsverktøy i utgangspunktet? Hvilken hensikt tjener det? Finnes det noen typer? Vel, la oss finne ut av det.
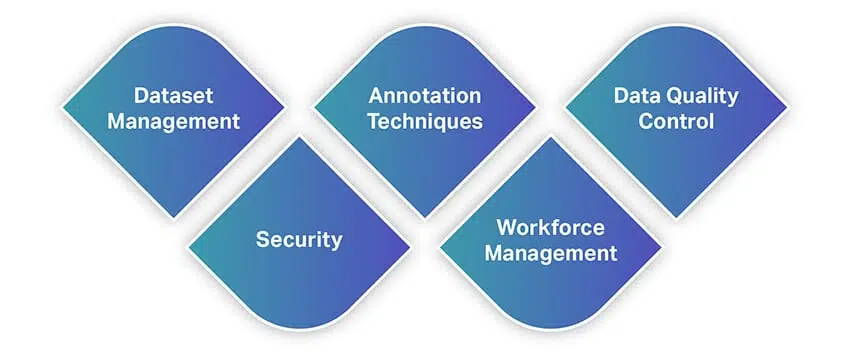
I likhet med andre verktøy tilbyr datakommentarverktøy et bredt spekter av funksjoner og muligheter. For å gi deg en rask idé om funksjoner, her er en liste over noen av de mest grunnleggende funksjonene du bør se etter når du velger et datamerkingsverktøy.
Datasettbehandling
Dataannoteringsverktøyet du har tenkt å bruke må støtte datasettene du har i hånden og la deg importere dem til programvaren for merking. Så administrasjon av datasettene dine er den primære funksjonen som verktøyene tilbyr. Moderne løsninger tilbyr funksjoner som lar deg importere store datavolumer sømløst, og samtidig lar deg organisere datasettene dine gjennom handlinger som sortering, filtrering, kloning, sammenslåing og mer.
Når inntastingen av datasettene dine er ferdig, er neste eksport av dem som brukbare filer. Verktøyet du bruker bør la deg lagre datasettene dine i formatet du angir, slik at du kan mate dem inn i ML-modellene dine.
Annoteringsteknikker
Dette er hva et datamerkingsverktøy er bygget eller designet for. Et solid verktøy bør tilby deg en rekke merknadsteknikker for datasett av alle typer. Dette er med mindre du utvikler en tilpasset løsning for dine behov. Verktøyet ditt skal la deg kommentere video eller bilder fra datasyn, lyd eller tekst fra NLP-er og transkripsjoner og mer. For å avgrense dette ytterligere, bør det være muligheter for å bruke grensebokser, semantisk segmentering, cuboids, interpolering, sentimentanalyse, orddeler, coreference-løsning og mer.
For de uinnvidde finnes det også AI-drevne datamerkingsverktøy. Disse kommer med AI-moduler som autonomt lærer av en annotators arbeidsmønstre og automatisk kommenterer bilder eller tekst. Slik
moduler kan brukes til å gi utrolig hjelp til kommentatorer, optimalisere merknader og til og med implementere kvalitetskontroller.
Datakvalitetskontroll
Når vi snakker om kvalitetssjekker, ruller flere datakommentarverktøy der ute med innebygde kvalitetskontrollmoduler. Disse lar annotatører samarbeide bedre med teammedlemmene og hjelper til med å optimalisere arbeidsflytene. Med denne funksjonen kan kommentatorer merke og spore kommentarer eller tilbakemeldinger i sanntid, spore identiteter bak personer som gjør endringer i filer, gjenopprette tidligere versjoner, velge å merke konsensus og mer.
Sikkerhet
Siden du jobber med data, bør sikkerhet ha høyeste prioritet. Du kan jobbe med konfidensielle data som de som involverer personlige opplysninger eller åndsverk. Så verktøyet ditt må gi lufttett sikkerhet når det gjelder hvor dataene er lagret og hvordan de deles. Den må tilby verktøy som begrenser tilgangen til teammedlemmer, forhindrer uautoriserte nedlastinger og mer.
Bortsett fra disse må sikkerhetsstandarder og protokoller oppfylles og overholdes.
Arbeidsstyring
Et datakommentarverktøy er også en slags prosjektstyringsplattform, der oppgaver kan tildeles teammedlemmer, samarbeid kan skje, vurderinger er mulig og mer. Det er derfor verktøyet ditt bør passe inn i arbeidsflyten og prosessen for optimalisert produktivitet.
Dessuten må verktøyet også ha en minimal læringskurve da prosessen med datakommentarer i seg selv er tidkrevende. Det tjener ingen hensikt å bruke for mye tid på å bare lære verktøyet. Så det skal være intuitivt og sømløst for alle å komme raskt i gang.
Hva er fordelene med datakommentarer?
Dataannotering er avgjørende for å optimalisere maskinlæringssystemer og levere forbedrede brukeropplevelser. Her er noen viktige fordeler med datakommentarer:
- Forbedret treningseffektivitet: Datamerking hjelper maskinlæringsmodeller med å bli bedre trent, forbedrer den generelle effektiviteten og gir mer nøyaktige resultater.
- Økt presisjon: Nøyaktig annoterte data sikrer at algoritmer kan tilpasse seg og lære effektivt, noe som resulterer i høyere presisjonsnivåer i fremtidige oppgaver.
- Redusert menneskelig intervensjon: Avanserte datakommentarverktøy reduserer behovet for manuell intervensjon betydelig, effektiviserer prosesser og reduserer tilknyttede kostnader.
Dermed bidrar datakommentarer til mer effektive og presise maskinlæringssystemer samtidig som kostnadene og den manuelle innsatsen som tradisjonelt kreves for å trene AI-modeller minimeres.
Å bygge eller ikke bygge et datakommentarverktøy
Et kritisk og overordnet problem som kan dukke opp under et datamerkings- eller datamerkingsprosjekt er valget om enten å bygge eller kjøpe funksjonalitet for disse prosessene. Dette kan komme opp flere ganger i ulike prosjektfaser, eller relatert til ulike deler av programmet. Når du velger om du vil bygge et system internt eller stole på leverandører, er det alltid en avveining.

Som du sannsynligvis kan se nå, er datakommentarer en kompleks prosess. Samtidig er det også en subjektiv prosess. Det betyr at det ikke finnes ett enkelt svar på spørsmålet om du bør kjøpe eller bygge et dataannoteringsverktøy. Mange faktorer må vurderes, og du må stille deg selv noen spørsmål for å forstå kravene dine og innse om du faktisk trenger å kjøpe eller bygge en.
For å gjøre dette enkelt, her er noen av faktorene du bør vurdere.
Ditt mål
Det første elementet du må definere er målet med kunstig intelligens og maskinlæringskonsepter.
- Hvorfor implementerer du dem i virksomheten din?
- Løser de et reell problem som kundene dine står overfor?
- Gjør de noen front-end eller backend prosess?
- Vil du bruke AI for å introdusere nye funksjoner eller optimalisere din eksisterende nettside, app eller en modul?
- Hva gjør din konkurrent i ditt segment?
- Har du nok brukstilfeller som trenger AI-intervensjon?
Svar på disse vil samle tankene dine – som for øyeblikket kan være over alt – på ett sted og gi deg mer klarhet.
AI-datainnsamling / lisensiering
AI-modeller krever bare ett element for å fungere – data. Du må identifisere hvor du kan generere enorme mengder bakkesannhetsdata. Hvis virksomheten din genererer store mengder data som må behandles for avgjørende innsikt om virksomhet, drift, konkurrentundersøkelser, markedsvolatilitetsanalyse, kundeatferdsstudie og mer, trenger du et dataannoteringsverktøy på plass. Du bør imidlertid også vurdere mengden data du genererer. Som nevnt tidligere, er en AI-modell bare så effektiv som kvaliteten og mengden av data den mates. Så avgjørelsene dine bør alltid avhenge av denne faktoren.
Hvis du ikke har de riktige dataene for å trene ML-modellene dine, kan leverandører komme godt med, og hjelpe deg med datalisensiering av det riktige settet med data som kreves for å trene ML-modeller. I noen tilfeller vil en del av verdien som leverandøren tilfører, involvere både teknisk dyktighet og også tilgang til ressurser som vil fremme prosjektsuksess.
budsjett
En annen grunnleggende betingelse som sannsynligvis påvirker hver enkelt faktor vi diskuterer nå. Løsningen på spørsmålet om du skal bygge eller kjøpe en dataannotering blir enkel når du forstår om du har nok budsjett å bruke.
Overholdelseskompleksiteter
 Leverandører kan være svært behjelpelige når det gjelder personvern og riktig håndtering av sensitive data. En av disse typene brukstilfeller involverer et sykehus eller en helserelatert virksomhet som ønsker å utnytte kraften til maskinlæring uten å sette samsvar med HIPAA og andre datavernregler i fare. Selv utenfor det medisinske feltet, strammer lover som den europeiske GDPR kontrollen over datasett, og krever mer årvåkenhet fra bedriftens interessenter.
Leverandører kan være svært behjelpelige når det gjelder personvern og riktig håndtering av sensitive data. En av disse typene brukstilfeller involverer et sykehus eller en helserelatert virksomhet som ønsker å utnytte kraften til maskinlæring uten å sette samsvar med HIPAA og andre datavernregler i fare. Selv utenfor det medisinske feltet, strammer lover som den europeiske GDPR kontrollen over datasett, og krever mer årvåkenhet fra bedriftens interessenter.
Manpower
Dataannotering krever dyktig arbeidskraft å jobbe med uavhengig av størrelsen, omfanget og domenet til virksomheten din. Selv om du genererer et minimum av data hver eneste dag, trenger du dataeksperter som jobber med dataene dine for merking. Så nå må du innse om du har den nødvendige arbeidskraften på plass. Hvis du gjør det, er de dyktige på de nødvendige verktøyene og teknikkene eller trenger de oppkvalifisering? Hvis de trenger oppkvalifisering, har du budsjett til å trene dem i utgangspunktet?
Dessuten tar de beste datamerkings- og datamerkingsprogrammene en rekke emne- eller domeneeksperter og segmenterer dem i henhold til demografi som alder, kjønn og ekspertiseområde – eller ofte i form av de lokaliserte språkene de skal jobbe med. Det er, igjen, der vi i Shaip snakker om å få de riktige personene på de riktige setene og dermed drive de riktige menneske-i-løkken-prosessene som vil lede din programmatiske innsats til suksess.
Små og store prosjektoperasjoner og kostnadsgrenser
I mange tilfeller kan leverandørstøtte være mer et alternativ for et mindre prosjekt, eller for mindre prosjektfaser. Når kostnadene er kontrollerbare, kan selskapet dra nytte av outsourcing for å gjøre datamerkings- eller datamerkingsprosjekter mer effektive.
Bedrifter kan også se på viktige terskler – der mange leverandører knytter kostnadene til mengden data som forbrukes eller andre ressursreferanser. La oss for eksempel si at et selskap har registrert seg hos en leverandør for å gjøre den kjedelige dataregistreringen som kreves for å sette opp testsett.
Det kan være en skjult terskel i avtalen der for eksempel forretningspartneren må ta ut en annen blokk med AWS-datalagring, eller en annen tjenestekomponent fra Amazon Web Services, eller en annen tredjepartsleverandør. Det gir de videre til kunden i form av høyere kostnader, og det setter prislappen utenfor kundens rekkevidde.
I disse tilfellene hjelper måling av tjenestene du får fra leverandører til å holde prosjektet rimelig. Å ha riktig omfang på plass vil sikre at prosjektkostnadene ikke overstiger det som er rimelig eller gjennomførbart for den aktuelle bedriften.
Alternativer for åpen kildekode og gratisprogram
 Noen alternativer til full leverandørstøtte involverer bruk av åpen kildekode-programvare, eller til og med freeware, for å gjennomføre datakommentarer eller merkeprosjekter. Her er det en slags mellomting der bedrifter ikke skaper alt fra bunnen av, men også unngår å stole for mye på kommersielle leverandører.
Noen alternativer til full leverandørstøtte involverer bruk av åpen kildekode-programvare, eller til og med freeware, for å gjennomføre datakommentarer eller merkeprosjekter. Her er det en slags mellomting der bedrifter ikke skaper alt fra bunnen av, men også unngår å stole for mye på kommersielle leverandører.
Gjør-det-selv-mentaliteten til åpen kildekode er i seg selv et slags kompromiss – ingeniører og interne personer kan dra nytte av åpen kildekode-fellesskapet, der desentraliserte brukerbaser tilbyr sine egne typer grasrotstøtte. Det vil ikke være som det du får fra en leverandør – du vil ikke få 24/7 enkel hjelp eller svar på spørsmål uten å gjøre intern research – men prislappen er lavere.
Så det store spørsmålet - Når bør du kjøpe et datamerkingsverktøy:
Som med mange typer høyteknologiske prosjekter, krever denne typen analyser – når de skal bygges og når de skal kjøpes – dedikert tankegang og vurdering av hvordan disse prosjektene hentes og administreres. Utfordringene de fleste bedrifter møter knyttet til AI/ML-prosjekter når de vurderer "bygg"-alternativet, er at det ikke bare handler om bygge- og utviklingsdelene av prosjektet. Det er ofte en enorm læringskurve for å komme til det punktet hvor ekte AI/ML-utvikling kan skje. Med nye AI/ML-team og initiativer oppveier antallet «ukjente ukjente» langt antallet «kjente ukjente».
| Bygge | Kjøp |
|---|---|
Pros:
| Pros:
|
Cons:
| Cons:
|
For å gjøre ting enda enklere, vurder følgende aspekter:
- når du jobber med enorme mengder data
- når du jobber med ulike typer data
- når funksjonene knyttet til modellene eller løsningene dine kan endres eller utvikles i fremtiden
- når du har en vag eller generisk brukssak
- når du trenger en klar idé om utgiftene forbundet med å distribuere et datamerkingsverktøy
- og når du ikke har den rette arbeidsstyrken eller dyktige eksperter til å jobbe med verktøyene og leter etter en minimal læringskurve
Hvis svarene dine var motsatte av disse scenariene, bør du fokusere på å bygge verktøyet ditt.
Hvordan velge riktig datamerkingsverktøy for prosjektet ditt
Hvis du leser dette, høres disse ideene spennende ut, og er definitivt lettere sagt enn gjort. Så hvordan går man frem for å utnytte overfloden av allerede eksisterende dataannoteringsverktøy der ute? Så det neste trinnet er å vurdere faktorene knyttet til å velge riktig datamerkingsverktøy.
I motsetning til for noen år tilbake, har markedet utviklet seg med tonnevis av datamerkingsverktøy i praksis i dag. Bedrifter har flere muligheter til å velge en basert på deres forskjellige behov. Men hvert enkelt verktøy kommer med sitt eget sett med fordeler og ulemper. For å ta en klok avgjørelse, må en objektiv rute også tas bortsett fra subjektive krav.
La oss se på noen av de avgjørende faktorene du bør vurdere i prosessen.
Definere brukstilfellet ditt
For å velge riktig dataannoteringsverktøy må du definere bruksområdet ditt. Du bør innse om kravet ditt involverer tekst, bilde, video, lyd eller en blanding av alle datatyper. Det er frittstående verktøy du kan kjøpe, og det er helhetlige verktøy som lar deg utføre forskjellige handlinger på datasett.
Verktøyene i dag er intuitive og gir deg muligheter når det gjelder lagringsfasiliteter (nettverk, lokalt eller sky), annoteringsteknikker (lyd, bilde, 3D og mer) og en rekke andre aspekter. Du kan velge et verktøy basert på dine spesifikke krav.
Etablering av kvalitetskontrollstandarder
 Dette er en avgjørende faktor å vurdere ettersom formålet og effektiviteten til AI-modellene dine er avhengig av kvalitetsstandardene du etablerer. Som en revisjon må du utføre kvalitetssjekker av dataene du mater inn og resultatene som er oppnådd for å forstå om modellene dine blir trent på riktig måte og til riktige formål. Spørsmålet er imidlertid hvordan du har tenkt å etablere kvalitetsstandarder?
Dette er en avgjørende faktor å vurdere ettersom formålet og effektiviteten til AI-modellene dine er avhengig av kvalitetsstandardene du etablerer. Som en revisjon må du utføre kvalitetssjekker av dataene du mater inn og resultatene som er oppnådd for å forstå om modellene dine blir trent på riktig måte og til riktige formål. Spørsmålet er imidlertid hvordan du har tenkt å etablere kvalitetsstandarder?
Som med mange forskjellige typer jobber, kan mange mennesker gjøre en datakommentar og tagging, men de gjør det med ulike grader av suksess. Når du ber om en tjeneste, bekrefter du ikke automatisk nivået på kvalitetskontroll. Det er derfor resultatene varierer.
Så, ønsker du å implementere en konsensusmodell, der annotatorer gir tilbakemelding om kvalitet og korrigerende tiltak blir iverksatt umiddelbart? Eller foretrekker du prøvegjennomgang, gullstandarder eller skjæringspunkt fremfor fagforeningsmodeller?
Den beste kjøpsplanen vil sikre at kvalitetskontrollen er på plass helt fra begynnelsen ved å sette standarder før en endelig kontrakt avtales. Når du etablerer dette, bør du ikke overse feilmarginer også. Manuell intervensjon kan ikke unngås helt, da systemene er bundet til å produsere feil med opptil 3 % rater. Dette krever arbeid i forkant, men det er verdt det.
Hvem vil kommentere dataene dine?
Den neste viktige faktoren er avhengig av hvem som kommenterer dataene dine. Har du tenkt å ha et internt team eller vil du heller få det outsourcet? Hvis du outsourcer, er det lovligheter og overholdelsestiltak du må vurdere på grunn av personvern- og konfidensialitetsbekymringer knyttet til data. Og hvis du har et internt team, hvor effektive er de til å lære et nytt verktøy? Hva er din time-to-market med produktet eller tjenesten din? Har du de riktige kvalitetsmålingene og teamene for å godkjenne resultatene?
Leverandøren vs. Partnerdebatt
 Dataannotering er en samarbeidsprosess. Det involverer avhengigheter og forviklinger som interoperabilitet. Dette betyr at visse team alltid jobber sammen med hverandre, og et av teamene kan være din leverandør. Derfor er leverandøren eller partneren du velger like viktig som verktøyet du bruker for datamerking.
Dataannotering er en samarbeidsprosess. Det involverer avhengigheter og forviklinger som interoperabilitet. Dette betyr at visse team alltid jobber sammen med hverandre, og et av teamene kan være din leverandør. Derfor er leverandøren eller partneren du velger like viktig som verktøyet du bruker for datamerking.
Med denne faktoren bør aspekter som evnen til å holde dataene og intensjonene dine konfidensielle, intensjon om å akseptere og jobbe med tilbakemeldinger, være proaktiv når det gjelder datarekvisisjoner, fleksibilitet i drift og mer, vurderes før du håndhilser på en leverandør eller en partner . Vi har inkludert fleksibilitet fordi kravene til datakommentarer ikke alltid er lineære eller statiske. De kan endre seg i fremtiden ettersom du skalerer virksomheten din ytterligere. Hvis du for øyeblikket bare arbeider med tekstbaserte data, kan det være lurt å kommentere lyd- eller videodata mens du skalerer, og støtten din skal være klar til å utvide horisonten med deg.
Leverandørens involvering
En av måtene å vurdere leverandørengasjement på er støtten du vil motta.
Enhver kjøpsplan må ta hensyn til denne komponenten. Hvordan vil støtte se ut på bakken? Hvem vil interessentene og pekende folk være på begge sider av ligningen?
Det er også konkrete oppgaver som må forklare hva leverandørens involvering er (eller vil være). For et datamerkings- eller datamerkingsprosjekt spesielt, vil leverandøren aktivt levere rådataene, eller ikke? Hvem vil fungere som sakkyndige, og hvem vil ansette dem enten som ansatte eller uavhengige kontraktører?
Casestudier
Her er noen konkrete eksempler på casestudier som tar for seg hvordan datamerking og datamerking virkelig fungerer på bakken. Hos Shaip sørger vi for å gi de høyeste kvalitetsnivåene og overlegne resultater innen datamerking og datamerking.
Mye av diskusjonen ovenfor om standardprestasjoner for datamerking og datamerking avslører hvordan vi nærmer oss hvert prosjekt, og hva vi tilbyr til selskapene og interessentene vi jobber med.
Casestudiemateriell som viser hvordan dette fungerer:

I et klinisk datalisensprosjekt behandlet Shaip-teamet over 6,000 timer med lyd, fjernet all beskyttet helseinformasjon (PHI) og etterlot HIPAA-kompatibelt innhold for helsevesenets talegjenkjenningsmodeller å jobbe med.
I denne typen saker er det kriteriene og klassifiseringen av prestasjoner som er viktige. Rådataene er i form av lyd, og det er behov for å avidentifisere parter. For eksempel, ved bruk av NER-analyse, er det doble målet å avidentifisere og kommentere innholdet.
En annen casestudie involverer en fordypning samtale AI treningsdata prosjekt som vi fullførte med 3,000 lingvister som jobbet over en 14-ukers periode. Dette førte til produksjon av opplæringsdata på 27 språk, for å utvikle flerspråklige digitale assistenter i stand til å håndtere menneskelig interaksjon på et bredt utvalg av morsmål.
I denne spesielle casestudien var behovet for å få rett person i rett stol tydelig. Det store antallet fageksperter og innholdsinputoperatører betydde at det var behov for organisering og prosessuell strømlinjeforming for å få prosjektet gjennomført på en bestemt tidslinje. Teamet vårt klarte å slå bransjestandarden med stor margin, gjennom å optimalisere innsamlingen av data og påfølgende prosesser.
Andre typer casestudier involverer ting som bottrening og tekstkommentarer for maskinlæring. Igjen, i et tekstformat er det fortsatt viktig å behandle identifiserte parter i henhold til personvernlovgivningen, og å sortere gjennom rådataene for å få de målrettede resultatene.
Med andre ord, ved å jobbe på tvers av flere datatyper og formater, har Shaip vist den samme viktige suksessen ved å bruke de samme metodene og prinsippene på både rådata og datalisensiering.