


Hva er Conversational AI
Conversational AI er en avansert form for kunstig intelligens som gjør det mulig for maskiner å delta i interaktive, menneskelignende dialoger med brukere. Denne teknologien forstår og tolker menneskelig språk for å simulere naturlige samtaler. Den kan lære av interaksjoner over tid for å reagere kontekstuelt.
Konversasjons-AI-systemer er mye brukt i applikasjoner som chatbots, taleassistenter og kundestøtteplattformer på tvers av digitale og telekommunikasjonskanaler.
Konversasjons-AI-markedet har opplevd rask vekst de siste årene. Opprinnelig utviklet for underholdningsformål, har konversasjons-AI blitt en integrert del av det digitale økosystemet. Her er noen nøkkelstatistikker for å illustrere virkningen:
- Det globale konversasjons-AI-markedet ble verdsatt til 6.8 milliarder dollar i 2021 og forventes å vokse til 18.4 milliarder dollar innen 2026 med en CAGR på 22.6 %. Innen 2028 forventes markedsstørrelsen å nå $ 29.8 milliarder.
- Til tross for utbredelsen, 63% av brukerne er uvitende om at de bruker kunstig intelligens i hverdagen.
- A Gartner undersøkelse fant ut at mange virksomheter identifiserte chatboter som deres primære AI-applikasjon, med nesten 70 % av funksjonærene forventet å samhandle med samtaleplattformer daglig innen 2022.
- Siden pandemien har volumet av interaksjoner håndtert av samtaleagenter økt med like mye som 250% på tvers av flere bransjer.
- Andelen markedsførere som bruker AI for digital markedsføring over hele verden økte dramatisk, fra 29 % i 2018 til 84% i 2020.
- I 2022, 91% av voksne stemmeassistentbrukere brukte konversasjons-AI-teknologi på smarttelefonene sine.
- Bla gjennom og søke etter produkter var det topp shoppingaktiviteter utført ved bruk av stemmeassistentteknologi blant amerikanske brukere i en undersøkelse fra 2021.
- Blant tekniske fagfolk over hele verden, nesten 80% bruke virtuelle assistenter for kundeservice.
- Innen 2024 tror 73 % av beslutningstakere i nordamerikansk kundeservice at nettchat, videochat, chatbots eller sosiale medier vil være mest brukte kundeservicekanaler.
- I en undersøkelse fra 2021, 86% av amerikanske ledere ble enige om at kunstig intelligens ville bli en "mainstream-teknologi" i selskapet deres.
- Fra februar 2022 53% av amerikanske voksne hadde kommunisert med en AI chatbot for kundeservice det siste året.
- I 2022, 3.5 milliarder chatbot-apper ble åpnet over hele verden.
- De topp tre grunner Amerikanske forbrukere bruker en chatbot for åpningstider (18 %), produktinformasjon (17 %) og kundeserviceforespørsler (16 %).
Denne statistikken fremhever den økende bruken og innflytelsen av samtale-AI på tvers av ulike bransjer og forbrukeratferd.
Hvordan fungerer Conversational AI
Conversational AI bruker naturlig språkbehandling (NLP) og andre sofistikerte algoritmer for å delta i kontekstrike dialoger. Ettersom AI møter et bredere spekter av brukerinndata, forbedrer den mønstergjenkjenningen og prediktive evner. Prosessen med konversasjons-AI som engasjerer brukere kan deles inn i fire nøkkeltrinn:

Trinn 1: Innsamling av inndata – Brukere gir innspill enten gjennom tekst eller tale.
Trinn 2: Inndatabehandling – Når input er i tekstform, brukes naturlig språkforståelse (NLU) for å trekke ut mening fra ordene. For stemmeinndata blir automatisk talegjenkjenning (ASR) først brukt for å konvertere lyd til språktokens som kan analyseres videre.
Trinn 3: Responsgenerering – Naturlige språkgenereringsteknikker brukes for å svare på brukerens henvendelse på riktig måte.
Trinn 4: Kontinuerlig forbedring – Konversasjons-AI-systemer analyserer brukerinndata over tid, og avgrenser svarene deres for å sikre nøyaktighet og relevans.

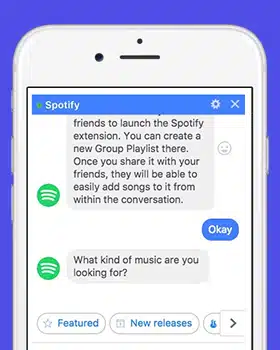
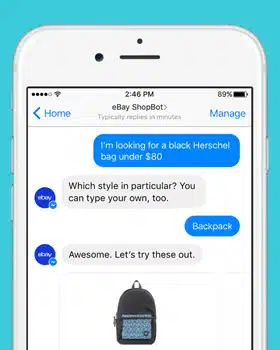

Redusere vanlige datautfordringer i Conversational AI
Conversational AI transformerer dynamisk kommunikasjon mellom mennesker og datamaskiner. Og mange virksomheter er opptatt av å utvikle avanserte AI-verktøy og applikasjoner for samtale som kan endre hvordan virksomheten gjøres. Men før du utvikler en chatbot som kan legge til rette for bedre kommunikasjon mellom deg og kundene dine, må du se på de mange utviklingsfellene du kan møte.
Språkmangfold
 Det er utfordrende å utvikle en chat-assistent som kan betjene flere språk. I tillegg gjør det store mangfoldet av globale språk det til en utfordring å utvikle en chatbot som sømløst gir kundeservice til alle kunder.
Det er utfordrende å utvikle en chat-assistent som kan betjene flere språk. I tillegg gjør det store mangfoldet av globale språk det til en utfordring å utvikle en chatbot som sømløst gir kundeservice til alle kunder.
I 2022, rundt 1.5 milliarder folk snakket engelsk over hele verden, etterfulgt av kinesisk mandarin med 1.1 milliarder høyttalere. Selv om engelsk er det mest talte og studerte fremmedspråket globalt, bare ca 20% av verdens befolkning snakker det. Det gjør at resten av verdens befolkning – 80 % – snakker andre språk enn engelsk. Så når du utvikler en chatbot, må du også vurdere språklig mangfold.
Språkvariabilitet
Mennesker snakker forskjellige språk og samme språk forskjellig. Dessverre er det fortsatt umulig for en maskin å fullt ut forstå talespråkets variasjon, med tanke på følelser, dialekter, uttale, aksenter og nyanser.
Våre ord og språkvalg gjenspeiles også i hvordan vi skriver. En maskin kan forventes å forstå og verdsette språkets variasjon bare når en gruppe annotatører trener den på forskjellige taledatasett.
Dynamisme i tale
En annen stor utfordring med å utvikle en samtale-AI er å bringe taledynamikk inn i kampen. For eksempel bruker vi flere fillers, pauser, setningsfragmenter og utydelige lyder når vi snakker. I tillegg er tale mye mer komplisert enn det skrevne ord, siden vi vanligvis ikke pauser mellom hvert ord og legger vekt på riktig stavelse.
Når vi lytter til andre, har vi en tendens til å utlede hensikten og meningen med samtalen deres ved å bruke våre livserfaringer. Som et resultat kontekstualiserer og forstår vi ordene deres selv når de er tvetydige. En maskin er imidlertid ikke i stand til denne kvaliteten.
Støyende data
Støyende data eller bakgrunnsstøy er data som ikke gir verdi til samtalene, for eksempel ringeklokker, hunder, barn og andre bakgrunnslyder. Derfor er det viktig å skrubbe eller filtrere lydfiler av disse lydene og trene AI-systemet til å identifisere lydene som betyr noe og de som ikke gjør det.
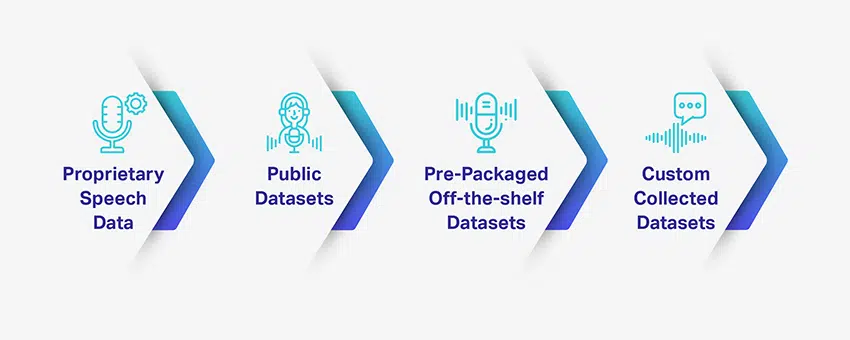
Fordeler og ulemper med forskjellige taledatatyper
 Å bygge et AI-drevet stemmegjenkjenningssystem eller en samtale-AI krever tonnevis med opplæring og testing av datasett. Det er imidlertid ikke lett å ha tilgang til slike kvalitetsdatasett – pålitelig og dekker dine spesifikke prosjektbehov. Likevel er det tilgjengelige alternativer for bedrifter som leter etter opplæringsdatasett, og hvert alternativ har fordeler og ulemper.
Å bygge et AI-drevet stemmegjenkjenningssystem eller en samtale-AI krever tonnevis med opplæring og testing av datasett. Det er imidlertid ikke lett å ha tilgang til slike kvalitetsdatasett – pålitelig og dekker dine spesifikke prosjektbehov. Likevel er det tilgjengelige alternativer for bedrifter som leter etter opplæringsdatasett, og hvert alternativ har fordeler og ulemper.
I tilfelle du leter etter en generisk datasetttype, har du mange offentlige talealternativer tilgjengelig. Men for noe mer spesifikt og relevant for prosjektkravet ditt, må du kanskje samle og tilpasse det på egen hånd.
Proprietære taledata
Det første stedet å lete ville være bedriftens proprietære data. Men siden du har den juridiske rettigheten og samtykket til å bruke kundetaledataene dine, kan du være i stand til å bruke dette enorme datasettet for opplæring og testing av prosjektene dine.
Pros:
- Ingen ekstra kostnader for innsamling av opplæringsdata
- Opplæringsdataene er sannsynligvis relevante for virksomheten din
- Taledata har også naturlig bakgrunnsakustikk, dynamiske brukere og enheter.
Cons:
- Bruk av slike data kan koste deg massevis av penger på tillatelse til å registrere og bruke.
- Taledataene kan ha språklige, demografiske eller kundebasebegrensninger
- Data kan være gratis, men du betaler fortsatt for behandlingen, transkripsjonen, merkingen og mer.
Offentlige datasett
Offentlige taledatasett er et annet alternativ hvis du ikke har tenkt å bruke ditt. Disse datasettene er en del av det offentlige domene og kan samles for åpen kildekode-prosjekter.
Pros:
- Offentlige datasett er gratis og ideelle for lavbudsjettprosjekter
- De er tilgjengelige for umiddelbar nedlasting
- Offentlige datasett kommer i en rekke skriptede og uskriptede eksempelsett.
Ulemper:
- Behandlings- og kvalitetssikringskostnadene kan være høye
- Kvaliteten på offentlige taledatasett varierer i betydelig grad
- Taleeksemplene som tilbys er vanligvis generiske, noe som gjør dem uegnet for å utvikle spesifikke taleprosjekter
- Datasettene er vanligvis partiske mot det engelske språket
Ferdigpakket/hyllevaredatasett
Utforsk ferdigpakkede datasett er et annet alternativ hvis offentlige data eller proprietære innsamling av taledata passer ikke dine behov.
Leverandøren har samlet ferdigpakkede taledatasett for det spesifikke formålet å videreselge til kunder. Denne typen datasett kan brukes til å utvikle generiske applikasjoner eller spesifikke formål.
Pros:
- Du kan få tilgang til et datasett som passer ditt spesifikke taledatabehov
- Det er rimeligere å bruke et ferdigpakket datasett enn å samle inn ditt eget
- Du kan kanskje få tilgang til datasettet raskt
Ulemper:
- Siden datasettet er ferdigpakket, er det ikke tilpasset prosjektbehovene dine.
- Dessuten er datasettet ikke unikt for din bedrift, da alle andre bedrifter kan kjøpe det.
Velg tilpassede innsamlede datasett
Når du bygger en taleapplikasjon, vil du kreve et opplæringsdatasett som oppfyller alle dine spesifikke krav. Det er imidlertid svært usannsynlig at du får tilgang til et ferdigpakket datasett som tilfredsstiller de unike kravene til prosjektet ditt. Det eneste tilgjengelige alternativet ville være å opprette datasettet ditt eller skaffe datasettet gjennom tredjepartsløsningsleverandører.
Datasettene for dine trenings- og testbehov kan tilpasses fullstendig. Du kan inkludere språkdynamikk, taledatavariasjon og tilgang til ulike deltakere. I tillegg kan datasettet skaleres for å møte prosjektkravene dine i tide.
Pros:
- Datasett samles inn for din spesifikke brukssituasjon. Sjansen for at AI-algoritmer avviker fra de tiltenkte resultatene er minimert.
- Kontroller og reduser skjevhet i AI-data
Ulemper:
- Datasettene kan være kostbare og tidkrevende; men fordelene oppveier alltid kostnadene.

Bransjer som bruker Conversational AI
For øyeblikket brukes konversasjons-AI hovedsakelig som Chatbots. Imidlertid implementerer flere bransjer denne teknologien for å oppnå store fordeler. Noen av bransjene som bruker konversasjons-AI er:
Helsevesen
 Conversational AI har en enorm innvirkning på helsesektoren. Conversational AI har vist seg å være gunstig for pasienter, leger, ansatte, sykepleiere og annet medisinsk personell.
Conversational AI har en enorm innvirkning på helsesektoren. Conversational AI har vist seg å være gunstig for pasienter, leger, ansatte, sykepleiere og annet medisinsk personell.
Noen av fordelene er
- Pasientengasjement i etterbehandlingsfasen
- Chatboter for avtaleplanlegging
- Svare på vanlige spørsmål og generelle henvendelser
- Symptomvurdering
- Identifiser kritiske pasienter
- Opptrapping av akutte tilfeller
E-handel
 Conversational AI hjelper e-handelsbedrifter med å engasjere seg med kundene sine, gi tilpassede anbefalinger og selge produkter.
Conversational AI hjelper e-handelsbedrifter med å engasjere seg med kundene sine, gi tilpassede anbefalinger og selge produkter.
E-handelsbransjen utnytter fordelene med denne klassens beste teknologi til det ytterste.
- Innhenting av kundeinformasjon
- Gi relevant produktinformasjon og anbefalinger
- Forbedring av kundetilfredshet
- Hjelper med å legge inn bestillinger og returer
- Svar på vanlige spørsmål
- Kryss- og mersalgsprodukter
Banking
 Banksektoren tar i bruk AI-verktøy for samtale for å forbedre kundeinteraksjoner, behandle forespørsler i sanntid og gi en forenklet og enhetlig kundeopplevelse på tvers av flere kanaler.
Banksektoren tar i bruk AI-verktøy for samtale for å forbedre kundeinteraksjoner, behandle forespørsler i sanntid og gi en forenklet og enhetlig kundeopplevelse på tvers av flere kanaler.
- Tillat kunder å sjekke saldoene sine i sanntid
- Hjelp med innskudd
- Bistå med å inngi skatt og søke om lån
- Strømlinjeform bankprosessen ved å sende regningspåminnelser, varsler og varsler
Forsikring
 I likhet med banksektoren, blir forsikringsbransjen også digitalt drevet av konversasjons-AI og høster fordelene. For eksempel hjelper samtale-AI forsikringsbransjen med raskere og mer pålitelige måter å løse konflikter og krav på.
I likhet med banksektoren, blir forsikringsbransjen også digitalt drevet av konversasjons-AI og høster fordelene. For eksempel hjelper samtale-AI forsikringsbransjen med raskere og mer pålitelige måter å løse konflikter og krav på.
- Gi retningslinjer for retningslinjer
- Raskere skadeoppgjør
- Eliminer ventetider
- Samle tilbakemeldinger og anmeldelser fra kunder
- Skap kundebevissthet om retningslinjer
- Administrer raskere krav og fornyelse

Shaip Offer
Når det gjelder å tilby kvalitets og pålitelige datasett for utvikling av avanserte taleapplikasjoner for menneske-maskin-interaksjon, har Shaip vært markedsledende med sine vellykkede distribusjoner. Men med en akutt mangel på chatbots og taleassistenter, søker bedrifter i økende grad tjenestene til Shaip – markedslederen – for å tilby tilpassede, nøyaktige og kvalitetsdatasett for opplæring og testing for AI-prosjekter.
Ved å kombinere naturlig språkbehandling kan vi gi personlige opplevelser ved å hjelpe til med å utvikle nøyaktige taleapplikasjoner som etterligner menneskelige samtaler effektivt. Vi bruker en rekke avanserte teknologier for å levere høykvalitets kundeopplevelser. NLP lærer maskiner å tolke menneskelige språk og samhandle med mennesker.
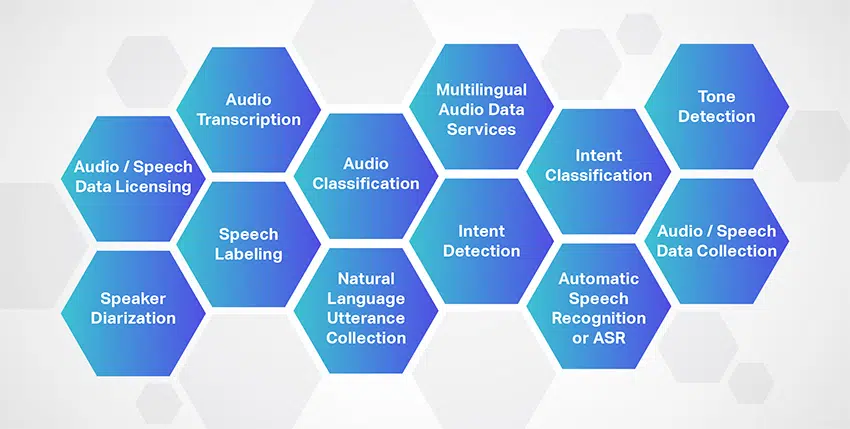
Lydtranskripsjon
Shaip er en ledende leverandør av lydtranskripsjonstjenester som tilbyr en rekke tale-/lydfiler for alle typer prosjekter. I tillegg tilbyr Shaip en 100 % menneskeskapt transkripsjonstjeneste for å konvertere lyd- og videofiler – intervjuer, seminarer, forelesninger, podcaster osv. til lett lesbar tekst.
Talemerking
Shaip tilbyr omfattende talemerkingstjenester ved å skille lydene og talen på en ekspert måte i en lydfil og merke hver fil. Ved nøyaktig å skille lignende lydlyder og kommentere dem,
Diaarisering av høyttaler
Sharps ekspertise strekker seg til å tilby utmerkede høyttalerdiariseringsløsninger ved å segmentere lydopptaket basert på deres kilde. Videre er høyttalergrensene nøyaktig identifisert og klassifisert, slik som høyttaler 1, høyttaler 2, musikk, bakgrunnsstøy, kjøretøylyder, stillhet og mer, for å bestemme antall høyttalere.
Lydklassifisering
Annotering begynner med å klassifisere lydfiler i forhåndsbestemte kategorier. Kategoriene avhenger først og fremst av prosjektets krav, og de inkluderer vanligvis brukerintensjon, språk, semantisk segmentering, bakgrunnsstøy, totalt antall høyttalere og mer.
Naturlig språk ytringssamling/ vekkeord
Det er vanskelig å forutsi at klienten alltid vil velge lignende ord når han stiller et spørsmål eller starter en forespørsel. For eksempel "Hvor er nærmeste restaurant?" "Finn restauranter i nærheten av meg" eller "Er det en restaurant i nærheten?"
Alle tre ytringene har samme hensikt, men er formulert forskjellig. Gjennom permutasjon og kombinasjon vil ekspertene for samtale-ai-spesialister hos Shaip identifisere alle mulige kombinasjoner som er mulige for å artikulere den samme forespørselen. Shaip samler inn og kommenterer ytringer og vekkeord, med fokus på semantikk, kontekst, tone, diksjon, timing, stress og dialekter.
Flerspråklige lyddatatjenester
Flerspråklige lyddatatjenester er et annet svært foretrukket tilbud fra Shaip, siden vi har et team av datainnsamlere som samler inn lyddata på over 150 språk og dialekter over hele verden.
Intensjonsdeteksjon
Menneskelig interaksjon og kommunikasjon er ofte mer komplisert enn vi gir dem æren for. Og denne medfødte komplikasjonen gjør det vanskelig å trene en ML-modell til å forstå menneskelig tale nøyaktig.
Dessuten kan forskjellige personer fra samme demografiske eller forskjellige demografiske grupper uttrykke den samme hensikten eller følelsen forskjellig. Så talegjenkjenningssystemet må trenes til å gjenkjenne felles hensikt uavhengig av demografi.
For å sikre at du kan trene og utvikle en førsteklasses ML-modell, tilbyr logopedene våre omfattende og varierte datasett for å hjelpe systemet med å identifisere de mange måtene mennesker uttrykker samme hensikt på.
Intens klassifisering
I likhet med å identifisere den samme hensikten fra forskjellige personer, bør chatbotene dine også trenes til å kategorisere kundekommentarer i ulike kategorier – forhåndsbestemt av deg. Hver chatbot eller virtuell assistent er designet og utviklet med et bestemt formål. Shaip kan klassifisere brukerintensjon i forhåndsdefinerte kategorier etter behov.
Automatisk talegjenkjenning eller ASR
Talegjenkjenning" refererer til å konvertere talte ord til teksten; imidlertid har stemmegjenkjenning og høyttaleridentifikasjon som mål å identifisere både talt innhold og høyttalerens identitet. ASRs nøyaktighet bestemmes av ulike parametere, dvs. høyttalervolum, bakgrunnsstøy, opptaksutstyr, etc.
Tonegjenkjenning
En annen interessant fasett av menneskelig interaksjon er tone - vi gjenkjenner i seg selv betydningen av ord avhengig av tonen de uttales med. Mens det vi sier er viktig, formidler hvordan vi sier disse ordene også mening.
For eksempel en enkel setning som "Hvilken glede!" kan være et utrop av lykke og kan også være ment å være sarkastisk. Det avhenger av tonen og stress.
'Hva gjør du?'
'Hva gjør du?'
Begge disse setningene har de nøyaktige ordene, men stresset på ordene er forskjellig, noe som endrer hele betydningen av setningene. Chatboten er opplært til å identifisere lykke, sarkasme, sinne, irritasjon og flere uttrykk. Det er her ekspertisen til Sharps talespråklige patologer og annotatorer kommer inn i bildet.
Lyd-/taledatalisensiering
Shaip tilbyr uovertruffen taledatasett av hyllekvalitet som kan tilpasses for å passe ditt prosjekts spesifikke behov. De fleste av våre datasett kan passe inn i ethvert budsjett, og dataene er skalerbare for å møte alle fremtidige prosjektkrav. Vi tilbyr mer enn 40 100 timer med hyllevare for taledatasett på over 50 dialekter på over XNUMX språk. Vi tilbyr også en rekke lydtyper, inkludert spontane ord, monologer, skriptede ord og vekkeord. Se hele Datakatalog.
Lyd / tale datainnsamling
Når det er mangel på kvalitetstaledatasett, kan den resulterende taleløsningen være full av problemer og mangle pålitelighet. Shaip er en av de få leverandørene som leverer flerspråklige lydsamlinger, lydtranskripsjon og merknadsverktøy og tjenester som er fullt tilpassbare for prosjektet.
Taledata kan sees på som et spektrum, fra naturlig tale i den ene enden til unaturlig tale i den andre. I naturlig tale har du taleren som snakker på en spontan samtalemåte. På den annen side høres unaturlig tale begrenset ut når høyttaleren leser av et manus. Til slutt blir høyttalere bedt om å si ord eller setninger på en kontrollert måte midt i spekteret.
Sharps ekspertise strekker seg til å tilby ulike typer taledatasett på over 150 språk

































Suksesshistorier
Vi har jobbet med noen av de beste virksomhetene og merkene og har gitt dem samtale-AI-løsninger av høyeste orden.
Noen av suksesshistoriene våre inkluderer,
- Vi hadde utviklet et talegjenkjenningsdatasett med mer enn 10,000 XNUMX timer med flerspråklige transkripsjoner, samtaler og lydfiler for å trene og bygge en live chatbot.
- Vi bygde et høykvalitets datasett med 1000-vis av samtaler på 6 svinger per samtale brukt til forsikrings chatbot-opplæring.
- Vårt team på 3000 pluss språkeksperter ga mer enn 1000 timer med lydfiler og transkripsjoner på 27 morsmål for opplæring og testing av en digital assistent.
- Vårt team av kommentatorer og språkeksperter samlet og leverte også 20,000 27 og flere timer med ytringer på mer enn XNUMX globale språk raskt.
- Våre automatiske talegjenkjenningstjenester er en av de mest foretrukne av bransjen. Vi leverte pålitelig merkede lydfiler, og sikret spesifikk oppmerksomhet til uttale, tone og hensikt ved å bruke et bredt spekter av transkripsjoner og leksikon fra forskjellige høyttalersett for å forbedre påliteligheten til ASR-modeller.
Våre suksesshistorier stammer fra teamets forpliktelse til å alltid tilby de beste tjenestene ved å bruke den nyeste teknologien til våre kunder. Det som gjør oss annerledes er at arbeidet vårt støttes av ekspertkommentarer som gir objektive og nøyaktige datasett med annoteringer av gullstandard.
Datainnsamlingsteamet vårt på over 30,000 XNUMX bidragsytere kan hente, skalere og levere datasett av høy kvalitet som hjelper til med rask distribusjon av ML-modeller. I tillegg jobber vi på den nyeste AI-baserte plattformen og har muligheten til å tilby akselererte taledataløsninger til bedrifter mye raskere enn våre nærmeste konkurrenter.
