
Nøkkelen til å overvinne AI-utviklingshindringer: Mer pålitelige data
I dag har en gjennomsnittlig person nå millioner av ganger mer datakraft i lomma enn NASA måtte gjennomføre månelandingen i 1969. Den samme allestedsnærværende enheten som praktisk demonstrerer en overflod av datakraft oppfyller også en annen forutsetning for AIs gullalder: en overflod av data. I følge innsikt fra Information Overload Research Group ble 90 % av verdens data opprettet i løpet av de siste to årene. Nå som den eksponentielle veksten i datakraft endelig har konvergert med like stor vekst i genereringen av data, eksploderer AI-datainnovasjoner så mye at noen eksperter tror vil sette i gang en fjerde industriell revolusjon.
Data fra National Venture Capital Association indikerer at AI-sektoren hadde en rekordstor investering på 6.9 milliarder dollar i første kvartal 2020. Det er ikke vanskelig å se potensialet til AI-verktøy fordi det allerede blir utnyttet rundt oss. Noen av de mer synlige brukstilfellene for AI-produkter er anbefalingsmotorene bak favorittapplikasjonene våre som Spotify og Netflix. Selv om det er morsomt å oppdage en ny artist å lytte til eller et nytt TV-program å overskue, er disse implementeringene ganske lave innsatser. Andre algoritmer vurderer testresultater – som delvis bestemmer hvor studenter blir tatt opp på college – og atter andre ser gjennom kandidat-CV'er og bestemmer hvilke søkere som får en bestemt jobb. Noen AI-verktøy kan til og med ha implikasjoner på liv eller død, for eksempel AI-modellen som screener for brystkreft (som overgår leger).
Til tross for jevn vekst i både virkelige eksempler på AI-utvikling og antallet startups som kjemper om å lage neste generasjon transformasjonsverktøy, gjenstår utfordringer for effektiv utvikling og implementering. Spesielt er AI-utdata bare så nøyaktig som inndata tillater, noe som betyr at kvaliteten er avgjørende.

Navigere i komplekse samsvarskrav
Som om det ikke var vanskelig nok å finne kvalitetsdata, er noen av bransjene som kan tjene mest på AI-datainnovasjoner også de strengest regulerte. Helsevesenet er kanskje det beste eksemplet, og mens en undersøkelse fra HIT Infrastructure fant at 91 % av industriinnsidere tror teknologien kan forbedre tilgangen til pleie, er den optimismen dempet av det faktum at 75 % ser det som en trussel mot pasientsikkerhet og personvern. – og pasienter er ikke de eneste i faresonen.
De omfattende forskriftene som er vedtatt gjennom Health Insurance Portability and Accountability Act, krysser nå ulike lokale hindringer for dataoverholdelse som Europas generelle databeskyttelsesforordning, California Consumer Privacy Act i USA og personopplysningsloven i Singapore. Disse lokale forskriftene vil få selskap av mange flere, og ettersom telehelse fremstår som en mer betydningsfull kilde til helsedata, er det sannsynlig at regelverket vil få et enda strammere grep om pasientdata under transport. Som et resultat vil Shaips sikre og kompatible skyplattform vise seg å være et enda mer verdifullt middel for å samle og få tilgang til helsedata for å trene AI-produkter.
Personlig identifiserbar informasjon kan være en betydelig trussel mot AI-utviklingen din, men selv en fullstendig kompatibel implementering er i fare hvis den ikke kan levere den typen nøyaktige resultater som bare kommer med forskjellige treningsdata. En studie fra 2020 i Journal of the American Medical Association viste at maskinlæringsalgoritmer i det medisinske feltet oftest trenes med data fra pasienter i California, New York og Massachusetts. Gitt at disse pasientene representerer mindre enn en femtedel av den amerikanske befolkningen, for ikke å si noe om resten av verden, er det vanskelig å forestille seg hvordan disse modellene kan gi noe annet enn partiske resultater.

 Shaip erkjenner vanskeligheten med å sikre samsvarende, geografisk mangfoldig informasjon, og tilbyr lisensierte helsetjenester fra en rekke regioner spesifikt kurert med sikte på å konstruere nøyaktige algoritmer. Disse dataene kommer i form av tekst, for eksempel medisinske journaler eller kravinformasjon, medisinsk diagnostisk bildebehandling som CT-skanninger, lyd som muntlige notater fra leger eller samtaler mellom leger og pasienter, og til og med video fra MR-resultater. Den er også fullstendig avidentifisert og anonymisert, og beskytter organisasjonen din mot både etiske og økonomiske implikasjoner som kan følge et brudd på noen av det økende antallet regelverk som styrer data av både nasjonal og internasjonal opprinnelse.
Shaip erkjenner vanskeligheten med å sikre samsvarende, geografisk mangfoldig informasjon, og tilbyr lisensierte helsetjenester fra en rekke regioner spesifikt kurert med sikte på å konstruere nøyaktige algoritmer. Disse dataene kommer i form av tekst, for eksempel medisinske journaler eller kravinformasjon, medisinsk diagnostisk bildebehandling som CT-skanninger, lyd som muntlige notater fra leger eller samtaler mellom leger og pasienter, og til og med video fra MR-resultater. Den er også fullstendig avidentifisert og anonymisert, og beskytter organisasjonen din mot både etiske og økonomiske implikasjoner som kan følge et brudd på noen av det økende antallet regelverk som styrer data av både nasjonal og internasjonal opprinnelse.
Overvinne hindringer for AI-utvikling
AI-utviklingsarbeid inkluderer betydelige hindringer uansett hvilken bransje de finner sted i, og prosessen med å komme fra en gjennomførbar idé til et vellykket produkt er full av vanskeligheter. Mellom utfordringene med å skaffe de riktige dataene og behovet for å anonymisere dem for å overholde alle relevante forskrifter, kan det føles som å faktisk konstruere og trene en algoritme er den enkle delen.
For å gi organisasjonen din alle nødvendige fordeler i arbeidet med å designe en banebrytende ny AI-utvikling, bør du vurdere å samarbeide med et selskap som Shaip. Chetan Parikh og Vatsal Ghiya grunnla Shaip for å hjelpe bedrifter med å utvikle den typen løsninger som kan forvandle helsevesenet i USA. Etter mer enn 16 år i virksomhet har selskapet vokst til å omfatte mer enn 600 teammedlemmer, og vi har jobbet med hundrevis av kunder for å gjøre overbevisende ideer om til AI-løsninger.
Med våre ansatte, prosesser og plattformer som jobber for organisasjonen din, kan du umiddelbart låse opp følgende fire fordeler og kaste prosjektet mot en vellykket avslutning:
1. Kapasiteten til å frigjøre dataforskerne dine
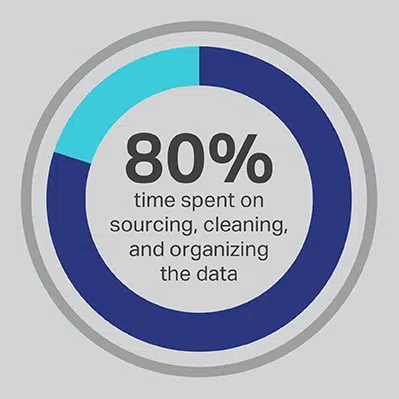
Det er ingen vei utenom at AI-utviklingsprosessen tar en betydelig investering av tid, men du kan alltid optimalisere funksjonene som teamet ditt bruker mest tid på å utføre. Du ansatte dataforskerne dine fordi de er eksperter på utvikling av avanserte algoritmer og maskinlæringsmodeller, men forskningen viser konsekvent at disse arbeiderne faktisk bruker 80 % av tiden sin på å hente inn, rense og organisere dataene som skal drive prosjektet. Mer enn tre fjerdedeler (76 %) av dataforskerne rapporterer at disse verdslige datainnsamlingsprosessene også tilfeldigvis er deres minst favorittdeler av jobben, men behovet for kvalitetsdata etterlater bare 20 % av tiden deres til faktisk utvikling, som er det mest interessante og intellektuelt stimulerende arbeidet for mange dataforskere. Ved å skaffe data gjennom en tredjepartsleverandør som Shaip, kan et selskap la sine dyre og talentfulle dataingeniører outsource arbeidet sitt som datavaktmestere og i stedet bruke tiden sin på de delene av AI-løsningene der de kan produsere mest verdi.
2. Evnen til å oppnå bedre resultater
 Mange AI-utviklingsledere bestemmer seg for å bruke åpen kildekode eller crowdsourced data for å redusere utgiftene, men denne beslutningen ender nesten alltid opp med å koste mer i det lange løp. Disse typer data er lett tilgjengelige, men de kan ikke matche kvaliteten på nøye utvalgte datasett. Spesielt Crowdsourced data er full av feil, utelatelser og unøyaktigheter, og selv om disse problemene noen ganger kan løses under utviklingsprosessen under våkne øyne av ingeniørene dine, krever det ytterligere iterasjoner som ikke ville vært nødvendig hvis du startet med høyere -kvalitetsdata fra begynnelsen.
Mange AI-utviklingsledere bestemmer seg for å bruke åpen kildekode eller crowdsourced data for å redusere utgiftene, men denne beslutningen ender nesten alltid opp med å koste mer i det lange løp. Disse typer data er lett tilgjengelige, men de kan ikke matche kvaliteten på nøye utvalgte datasett. Spesielt Crowdsourced data er full av feil, utelatelser og unøyaktigheter, og selv om disse problemene noen ganger kan løses under utviklingsprosessen under våkne øyne av ingeniørene dine, krever det ytterligere iterasjoner som ikke ville vært nødvendig hvis du startet med høyere -kvalitetsdata fra begynnelsen.
Å stole på åpen kildekode-data er en annen vanlig snarvei som kommer med sitt eget sett med fallgruver. Mangel på differensiering er et av de største problemene, fordi en algoritme som er trent ved bruk av åpen kildekode-data, er lettere å replikere enn en bygd på lisensierte datasett. Ved å gå denne ruten inviterer du til konkurranse fra andre aktører i området som kan underby prisene dine og ta markedsandeler når som helst. Når du stoler på Shaip, får du tilgang til data av høyeste kvalitet samlet av en dyktig administrert arbeidsstyrke, og vi kan gi deg en eksklusiv lisens for et tilpasset datasett som hindrer konkurrenter i å enkelt gjenskape din hardt vunnede intellektuelle eiendom.
3. Tilgang til erfarne fagfolk
 Selv om din interne liste inkluderer dyktige ingeniører og talentfulle dataforskere, kan AI-verktøyene dine dra nytte av visdommen som bare kommer gjennom erfaring. Våre fageksperter har stått i spissen for en rekke AI-implementeringer på sine felt og lært verdifulle leksjoner underveis, og deres eneste mål er å hjelpe deg med å oppnå ditt.
Selv om din interne liste inkluderer dyktige ingeniører og talentfulle dataforskere, kan AI-verktøyene dine dra nytte av visdommen som bare kommer gjennom erfaring. Våre fageksperter har stått i spissen for en rekke AI-implementeringer på sine felt og lært verdifulle leksjoner underveis, og deres eneste mål er å hjelpe deg med å oppnå ditt.
Med domeneeksperter som identifiserer, organiserer, kategoriserer og merker data for deg, vet du at informasjonen som brukes til å trene algoritmen din kan gi best mulig resultater. Vi gjennomfører også regelmessig kvalitetssikring for å sikre at data oppfyller de høyeste standardene og vil fungere etter hensikten, ikke bare i et laboratorium, men også i en virkelig situasjon.
4. En akselerert utviklingstidslinje
AI-utvikling skjer ikke over natten, men det kan skje raskere når du samarbeider med Shaip. Intern datainnsamling og merknader skaper en betydelig operasjonell flaskehals som holder opp resten av utviklingsprosessen. Å jobbe med Shaip gir deg umiddelbar tilgang til vårt enorme bibliotek med klar-til-bruk data, og ekspertene våre vil kunne hente alle slags tilleggsdata du trenger med vår dype bransjekunnskap og globale nettverk. Uten byrden med innkjøp og merknader kan teamet ditt begynne å jobbe med faktisk utvikling med en gang, og opplæringsmodellen vår kan bidra til å identifisere tidlige unøyaktigheter for å redusere gjentakelsene som er nødvendige for å nå nøyaktighetsmålene.
Hvis du ikke er klar til å outsource alle aspekter av dataadministrasjonen din, tilbyr Shaip også en skybasert plattform som hjelper team med å produsere, endre og kommentere ulike typer data mer effektivt, inkludert støtte for bilder, video, tekst og lyd . ShaipCloud inkluderer en rekke intuitive validerings- og arbeidsflytverktøy, for eksempel en patentert løsning for å spore og overvåke arbeidsbelastninger, et transkripsjonsverktøy for å transkribere komplekse og vanskelige lydopptak, og en kvalitetskontrollkomponent for å sikre kompromissløs kvalitet. Det beste av alt er at det er skalerbart, så det kan vokse etter hvert som de ulike kravene til prosjektet ditt øker.
Tiden for AI-innovasjon har bare så vidt begynt, og vi vil se utrolige fremskritt og innovasjoner i de kommende årene som har potensial til å omforme hele bransjer eller til og med endre samfunnet som helhet. Hos Shaip ønsker vi å bruke ekspertisen vår til å tjene som en transformativ kraft, og hjelpe de mest revolusjonerende selskapene i verden med å utnytte kraften til AI-løsninger for å oppnå ambisiøse mål.
Vi har dyp erfaring innen helseapplikasjoner og samtale-AI, men vi har også de nødvendige ferdighetene til å trene modeller for nesten alle typer applikasjoner. For mer informasjon om hvordan Shaip kan hjelpe deg med å ta prosjektet ditt fra idé til implementering, ta en titt på de mange ressursene som er tilgjengelige på nettsiden vår eller ta kontakt med oss i dag.
