

Intelligente AI-modeller må trenes grundig for å kunne identifisere mønstre, objekter og til slutt ta pålitelige beslutninger. De trente dataene kan imidlertid ikke mates tilfeldig og må merkes for å hjelpe modellene til å forstå, behandle og lære omfattende fra de kurerte inndatamønstrene.
Det er her datamerking kommer inn, som en handling for å merke informasjon eller snarere metadata, i henhold til et spesifikt datasett, for å fokusere på å forsterke forståelsen av maskinene. For ganske enkelt å gå videre, kategoriserer datamerking selektivt data, bilder, tekst, lyd, videoer og mønstre for å forbedre AI-implementeringer.
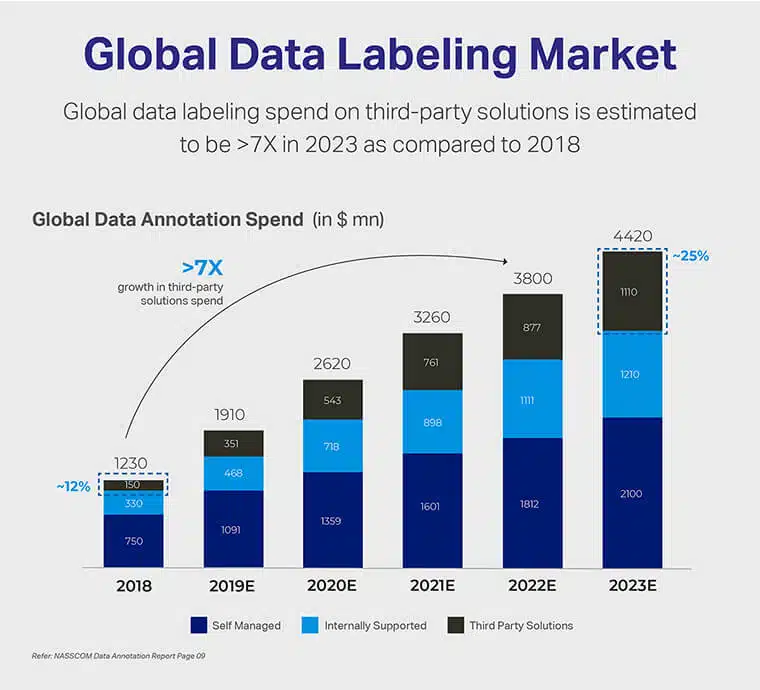
Per NASSCOM Datamerking Rapporter at det globale datamerkingsmarkedet forventes å vokse med 700 % i verdi innen utgangen av 2023, sammenlignet med 2018. Denne påståtte veksten vil mest sannsynlig ta hensyn til den økonomiske allokeringen for selvstyrte merkeverktøy, internt støttet ressurser, og til og med tredjepartsløsninger.
I tillegg til disse funnene kan det også utledes at det globale datamerkingsmarkedet samlet en verdi på 1.2 milliarder dollar i 2018. Vi forventer imidlertid at det vil skalere ettersom størrelsen på datamerkingsmarkedet antas å nå en massiv verdi på 4.4 milliarder dollar innen 2023.
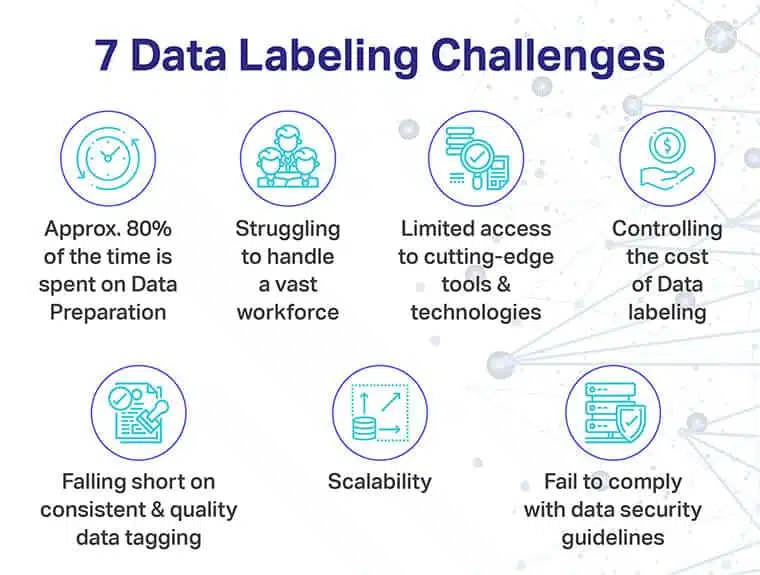
Datamerking er tidens behov, men kommer med flere implementerings- og prisspesifikke utfordringer.
Noen av de mer presserende inkluderer:
- Treg dataforberedelse, takket være overflødige renseverktøy
- Mangel på nødvendig maskinvare for å håndtere en massiv arbeidsstyrke og for store mengder skrapte data
- Begrenset tilgang til avantgarde merkeverktøy og støtteteknologi
- Høyere kostnad for datamerking
- Mangel på konsistens når det gjelder merking av kvalitetsdata
- Mangel på skalerbarhet, hvis og når AI-modellen trenger å dekke et ekstra sett med deltakere
- Mangel på samsvar når det gjelder å opprettholde en jevn datasikkerhetsstilling mens du anskaffer data og bruker dem

Selv om du kan skille datamerking konseptuelt, krever de relevante verktøyene at du klassifiserer konseptene i henhold til datasettenes natur. Disse inkluderer:
- Lydklassifisering: Omfatter lydinnsamling, segmentering og transkripsjon
- Bildemerking: Inneholder innsamling, klassifisering, segmentering og merking av nøkkeldata
- Tekstmerking: Innebærer tekstutvinning og klassifisering
- Videomerking: Inkluderer elementer som videoinnsamling, klassifisering og segmentering
- 3D-merking: Har objektsporing og segmentering
Bortsett fra den nevnte segregeringen, spesielt fra et bredere perspektiv, er datamerking delt inn i fire typer, inkludert beskrivende, evaluerende, informativ og kombinasjon. Men for det eneste formålet med opplæring, er datamerking segregert som: innsamling, segmentering, transkripsjon, Klassifisering, utvinning, objektsporing, som vi allerede har diskutert for de enkelte datasettene.

Datamerking er en detaljert prosess og involverer følgende trinn for å kategorisk trene AI-modeller:
- Innsamling av datasett, via strategier, dvs. internt, åpen kildekode, leverandører
- Merking av datasett i henhold til Computer Vision, Deep learning og NLP-spesifikke evner
- Testing og evaluering av produserte modeller for å bestemme intelligens som en del av distribusjon
- Tilfredsstiller akseptabel modellkvalitet og frigjør den til slutt for omfattende bruk

Det riktige settet med datamerkingsverktøy, synonymt med en troverdig datamerkingsplattform, må velges med tanke på følgende faktorer:
- Type intelligens du ønsker at modellen skal ha via definerte brukstilfeller
- Kvalitet og erfaring til dataannotatorer, slik at de kan bruke verktøyene til presisjon
- Kvalitetsstandarder du har i tankene
- Samsvarsspesifikke behov
- Kommersielle, åpen kildekode og freeware-verktøy
- Budsjett du kan spare
I tillegg til de nevnte faktorene, er det bedre å notere seg følgende hensyn:
- Merkenøyaktighet av verktøyene
- Kvalitetssikring er garantert av verktøyene
- Integrasjonsevner
- Sikkerhet og immunisering mot lekkasjer
- Skybasert oppsett eller ikke
- Kvalitetskontroll ledelsessans
- Fail-Safes, Stop-Gaps og skalerbar dyktighet til verktøyet
- Selskapet som tilbyr verktøyene
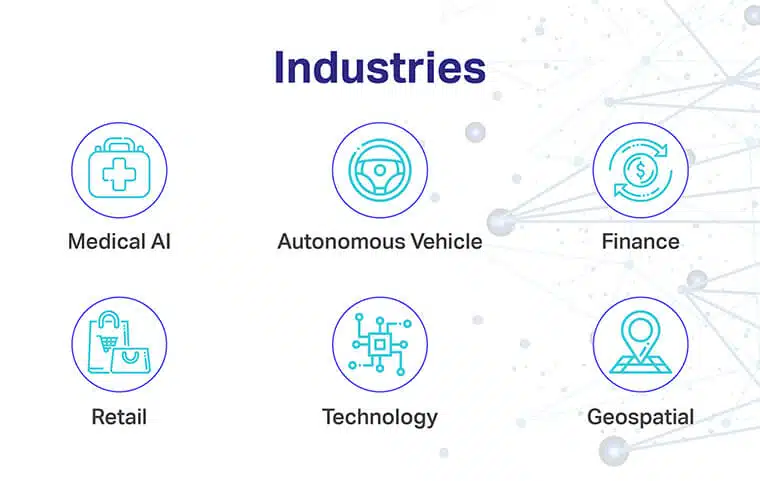
Vertikaler som er best tjent med datamerkingsverktøy og ressurser inkluderer:
- Medisinsk AI: Fokusområder inkluderer trening av diagnostiske modeller med datasyn for forbedret medisinsk bildebehandling, minimale ventetider og minimalt etterslep
- Finans: Fokusområder inkluderer evaluering av kredittrisiko, lånekvalifisering og andre viktige faktorer via tekstmerking
- Autonomt kjøretøy eller transport: Fokusområder inkluderer implementering av NLP og Computer Vision for å stable modeller med et vanvittig volum av treningsdata for å oppdage individer, signaler, blokader, etc.
- Detaljhandel og e-handel: Fokusområder inkluderer prisspesifikke beslutninger, forbedret e-handel, overvåking av kjøperpersonlighet, forståelse av kjøpsvaner og forsterket brukeropplevelse
- Teknologi: Fokusområder inkluderer produktproduksjon, søppelplukking, oppdage kritiske produksjonsfeil på forhånd og mer
- Geospatial: Fokusområder inkluderer GPS og fjernmåling ved hjelp av utvalgte merketeknikker
- Jordbruk: Fokusområder inkluderer bruk av GPS-sensorer, droner og datasyn for å fremme konseptene for presisjonslandbruk, optimalisere jord- og avlingsforhold, bestemme avlinger og mer

Fortsatt forvirret om hva som er en bedre strategi for å få datamerking på rett spor, dvs. bygge et selvstyrt oppsett eller kjøpe et fra en tredjeparts tjenesteleverandør. Her er fordelene og ulempene med hver for å hjelpe deg med å bestemme bedre:
'Bygge'-tilnærmingen
| Bygge | Kjøp |
|---|---|
Treff:
| Treff:
|
Misses:
| Misses:
|
Fordeler:
| Fordeler:
|
Kjennelse
Hvis du planlegger å bygge et eksklusivt AI-system uten at tiden er en begrensning, er det fornuftig å bygge et merkeverktøy fra bunnen av. For alt annet er det å kjøpe et verktøy den beste tilnærmingen


