
Har du noen gang lurt på hvordan chatboter og virtuelle assistenter våkner når du sier «Hei Siri» eller «Alexa»? Det er på grunn av innsamlingen av tekstytringer eller utløser ord innebygd i programvaren som aktiverer systemet så snart det hører det programmerte våkneordet.
Den generelle prosessen med å lage lyder og ytringsdata er imidlertid ikke så enkel. Det er en prosess som må gjennomføres med riktig teknikk for å få ønsket resultat. Derfor vil denne bloggen dele veien til å lage gode ytringer/triggerord som fungerer sømløst med din samtale-AI.
Hva er ytringer?
Ytringer kan refereres til som fraser eller triggerord som brukes til å aktivere en kunstig intelligent modell. Når AI-modellen din oppdager våkenordet, begynner den automatisk å registrere brukerens neste forespørsel og svarer med en passende handling eller svar.
Utterance bruker konseptet dyp læring for å lære programvaren hvordan den gjenkjenner våkne ord. Når wake word aktiverer programvaren, begynner systemet å fange, dekode og betjene forespørselen. Når det ikke er i bruk, fortsetter systemet passivt å lytte etter triggerord.
For at AI-programvaren din skal oppnå nøyaktige resultater, er det viktig å fange opp en mengde forskjellige ytringer for enhver hensikt. Det hjelper med bedre trening for AI-modellen.
[Les også: Vil du vite hvordan Siri og Alexa forstår deg?]
Poeng å huske når du oppretter et arkiv med ytringer
Nå som vi vet at trening er viktig for AI-modeller, er neste ting å vite hvordan man kan gi ytringer til AI-modellene. Vanligvis opprettes et arkiv med ytringer for å trene samtale-AIer.
Det er imidlertid forskjellige ting å huske på når du bygger arkiver for ytringer. Følgende er ting du bør vurdere:
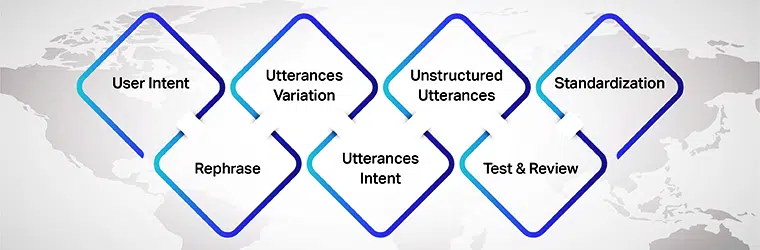
Brukerhensikt
Først og fremst mens du forbereder ytringer for AI-modellen din, sørg for at du forstår brukerhensikten du utvikler datasettene for. Du må finne ut de forskjellige ytringene som brukere kan skrive inn mens de snakker med AI-modellen.
Variasjon av ytringer
Variasjoner er en viktig del av denne prosessen, ettersom jo flere variasjoner for hver hensikt, jo bedre resultater vil du oppnå. Så sørg for å lage flere varianter av brukerytringer. Du kan gjøre det ved å
- Lage korte, mellomstore og store setninger for de samme setningene.
- Endre ordene og lengden på setninger.
- Bruke unike ord.
- Pluralisering av setningene.
- Blander sammen grammatikken.



