


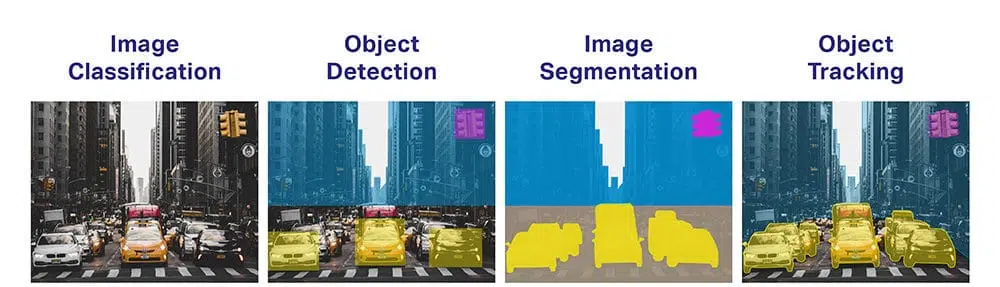
- Objektklassifisering: Hvilken bred kategori av objekter er det?
- Objektidentifikasjon: Hvilken type av et gitt objekt finnes det?
- Objektbekreftelse: Hva er objektet på bildet?
- Objektgjenkjenning: Hvor er objektene på bildet?
- Deteksjon av objekt landemerke: Hva er hovedpunktene for objektet på fotografiet?
- Objektsegmentering: Hvilke piksler tilhører objektet i bildet?
- Objektgjenkjenning: Hvilke gjenstander er på dette bildet og hvor er de?

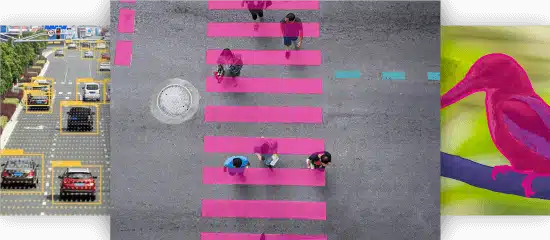


Bildesamling

Videoinnsamling

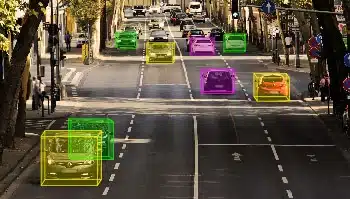
Avgrensende bokser
3D Cuboids
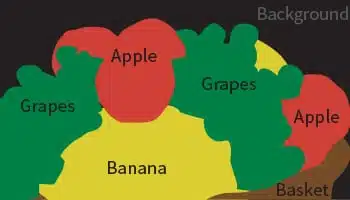
Semantisk segmentering

Polygonkommentar

Merkemerke

Linjesegmentering

Bildetranskripsjon
Videotransskripsjon

Bildeklassifisering
Bildesegmentering

Bilde nøkkelpunktkommentar

Videoklassifisering
Videosegmentering

- Bruk sak: ADAS-modell i bilen
- Format: Bilder
- Volum: 455,000 +
- merknad: Nei

- Bruk sak: Landmerkegjenkjenning
- Format: Bilder
- Volum: 80,000 +
- merknad: Nei

- Bruk sak: Spor for fotgjengere
- Format: videoer
- Volum: 84,500 +
- merknad: Ja

- Bruk sak: Matgjenkjenning
- Format: Bilder
- Volum: 55,000 +
- merknad: Ja

Helsevesenet AI
Tren ML-modeller til å oppdage kreftføflekker i hudbilder eller finne symptomer i MR-skanning eller pasientens røntgen.

ansiktsgjenkjenning
Tren ML-modeller til å identifisere bilder av mennesker basert på ansiktstrekk og sammenlign dem med en database med ansiktsprofiler for å oppdage og merke personer.

Geospatiale applikasjoner
Annotering av satellittbilder og UAV-fotografering for å forberede datasett for geoprosessering, og kommentere 3D-punktsky for Geo.AI.

Augmented Reality
Med AR-headset kan du plassere virtuelle objekter i den virkelige verden. Den kan oppdage plane overflater som vegger, bordplater og gulv - en svært kritisk del i å etablere dybde og dimensjoner og plassere virtuelle objekter i den fysiske verden.

Selvkjørende biler
Flere kameraer tar opp videoer fra en annen vinkel for å identifisere grensene for trafikksignaler, veier, biler, gjenstander og fotgjengere i nærheten for å trene de selvkjørende bilene til å autostyre kjøretøyet og unngå å treffe hindringer mens de kjører passasjeren trygt.

Detaljhandel / e-handel
Med datasyn i detaljhandelen, kan applikasjonene tilby personlige anbefalinger basert på kunders kjøpsmønstre og fremskynde forretningsdrift som hylleadministrasjon, betalinger etc.




porsjoner
Dedikerte og trente team:
- 30,000+ samarbeidspartnere for dataskaping, merking og kvalitetssikring
- Godkjent prosjektlederteam
- Erfarent produktutviklingsteam
- Talentpool-innkjøps- og onboarding-team

Prosess
Høyeste prosesseffektivitet er sikret med:
- Robust 6 Sigma Stage-Gate-prosess
- Et dedikert team av 6 Sigma svarte belter – nøkkelprosesseiere og overholdelse av kvalitet
- Kontinuerlig forbedring og tilbakemeldingssløyfe

Plattform
Den patenterte plattformen tilbyr fordeler:
- Nettbasert ende-til-ende-plattform
- Upåklagelig kvalitet
- Raskere TAT
- Sømløs levering
porsjoner
Dedikerte og trente team:
- 30,000+ samarbeidspartnere for dataskaping, merking og kvalitetssikring
- Godkjent prosjektlederteam
- Erfarent produktutviklingsteam
- Talentpool-innkjøps- og onboarding-team
Prosess
Høyeste prosesseffektivitet er sikret med:
- Robust 6 Sigma Stage-Gate-prosess
- Et dedikert team av 6 Sigma svarte belter – nøkkelprosesseiere og overholdelse av kvalitet
- Kontinuerlig forbedring og tilbakemeldingssløyfe
Plattform
Den patenterte plattformen tilbyr fordeler:
- Nettbasert ende-til-ende-plattform
- Upåklagelig kvalitet
- Raskere TAT
- Sømløs levering