






Tekstsamling

Lyd/talesamling
Tekstkommentar
Lyd / talekommentar

Teksttranskripsjon

Lyd / tale transkripsjon




Conversational AI / Chatbot Training
Opplæring av digitale assistenter krever et stort sett med kvalitetsdata fra forskjellige geografier, språk, dialekter, oppsett og formater. Hos Shaip tilbyr vi opplæringsdata for AI-modeller med Human-in-the-loop som har den nødvendige kunnskapen, domeneekspertisen og er godt klar over de spesifikke behovene til kunden.
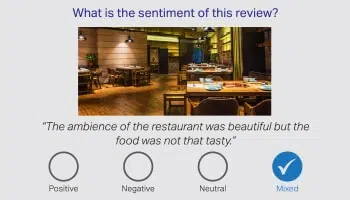
Sentiment / hensikt
Analyse
Det sies med rette at ord alene ikke klarer å formidle hele historien, og det er menneskelige kommentatorer som har ansvaret for å tolke tvetydigheten i menneskelig språk. Derfor er det ytterst viktig å identifisere følelsen til en kunde, basert på samtalen. Våre språkeksperter fra ulike domener kan tolke nyanser i produktanmeldelser, finansnyheter og sosiale medier.

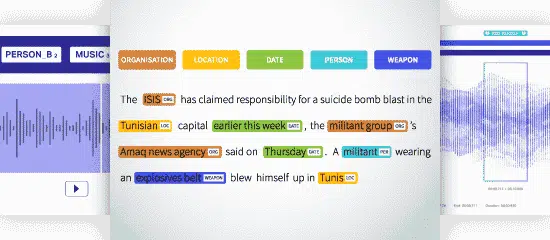
Navngitt entitetsgjenkjenning (NER)
Named Entity Recognition (NER) er å identifisere, trekke ut og klassifisere de navngitte enhetene i en tekst, i forhåndsdefinerte kategorier. Teksten kan kategoriseres som et sted, navn, organisasjon, produkt, mengde, verdi, prosent, osv. Med NER kan du ta opp spørsmål fra den virkelige verden som hvilke organisasjoner som ble nevnt i artikkelen osv.
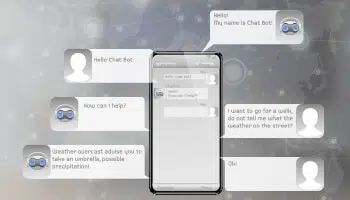
Kundeserviceautomatisering
Robuste, godt trente virtuelle chatboter eller digitale assistenter har revolusjonert måten kundene kommuniserer med selgerne på, og har bidratt til en betydelig forbedring i kundeopplevelsen.

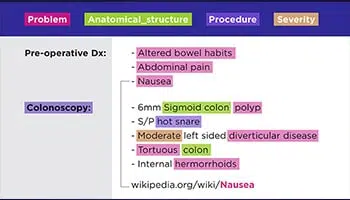
Teksttranskripsjon
Fra legers håndskrevne resepter til notater fra telefonkonferanser, våre spesialister kan digitalisere alle former for data, f.eks. arkiverte dokumenter, juridiske kontrakter, pasientjournaler, etc.
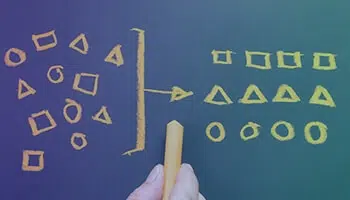
Innholdskategorisering
Kategorisering også kjent som klassifisering eller tagging er prosessen med å klassifisere tekst i organiserte grupper og merke den, basert på dens funksjoner av interesse.

Emneanalyse
Emneanalyse eller emnemerking er å identifisere og trekke ut mening fra en gitt tekst ved å identifisere tilbakevendende emner/temaer som vurderes.

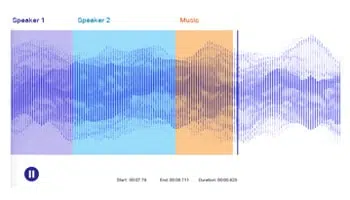
Lydtranskripsjon
Transkriber tale/podcast/seminar, ring samtale til tekst. Utnytt mennesker til å kommentere lyd-/talefiler nøyaktig for å trene NLP-modeller nøyaktig.

Lydklassifisering
Kategoriser lyder eller ytringer for å klassifisere tale/lyd basert på språk, dialekt, semantikk, leksikon osv.

porsjoner
Dedikerte og trente team:
- 30,000+ samarbeidspartnere for dataskaping, merking og kvalitetssikring
- Godkjent prosjektlederteam
- Erfarent produktutviklingsteam
- Talentpool-innkjøps- og onboarding-team

Prosess
Høyeste prosesseffektivitet er sikret med:
- Robust 6 Sigma Stage-Gate-prosess
- Et dedikert team av 6 Sigma svarte belter – nøkkelprosesseiere og overholdelse av kvalitet
- Kontinuerlig forbedring og tilbakemeldingssløyfe

Plattform
Den patenterte plattformen tilbyr fordeler:
- Nettbasert ende-til-ende-plattform
- Upåklagelig kvalitet
- Raskere TAT
- Sømløs levering


