

Hva er store språkmodeller?
Large Language Models (LLM) er avanserte systemer for kunstig intelligens (AI) designet for å behandle, forstå og generere menneskelignende tekst. De er basert på dyplæringsteknikker og trent på massive datasett, som vanligvis inneholder milliarder av ord fra forskjellige kilder som nettsteder, bøker og artikler. Denne omfattende opplæringen gjør det mulig for LLM-er å forstå nyansene til språk, grammatikk, kontekst og til og med noen aspekter av generell kunnskap.
Noen populære LLM-er, som OpenAIs GPT-3, bruker en type nevrale nettverk kalt en transformator, som lar dem håndtere komplekse språkoppgaver med bemerkelsesverdig dyktighet. Disse modellene kan utføre et bredt spekter av oppgaver, for eksempel:
- Svare på spørsmål
- Oppsummerende tekst
- Oversetter språk
- Generer innhold
- Selv delta i interaktive samtaler med brukere
Ettersom LLM-er fortsetter å utvikle seg, har de et stort potensial for å forbedre og automatisere ulike applikasjoner på tvers av bransjer, fra kundeservice og innholdsskaping til utdanning og forskning. Imidlertid reiser de også etiske og samfunnsmessige bekymringer, for eksempel partisk oppførsel eller misbruk, som må tas opp etter hvert som teknologien skrider frem.

Populære eksempler på store språkmodeller
Her er noen fremtredende eksempler på LLM-er som brukes mye i forskjellige industrivertikaler:
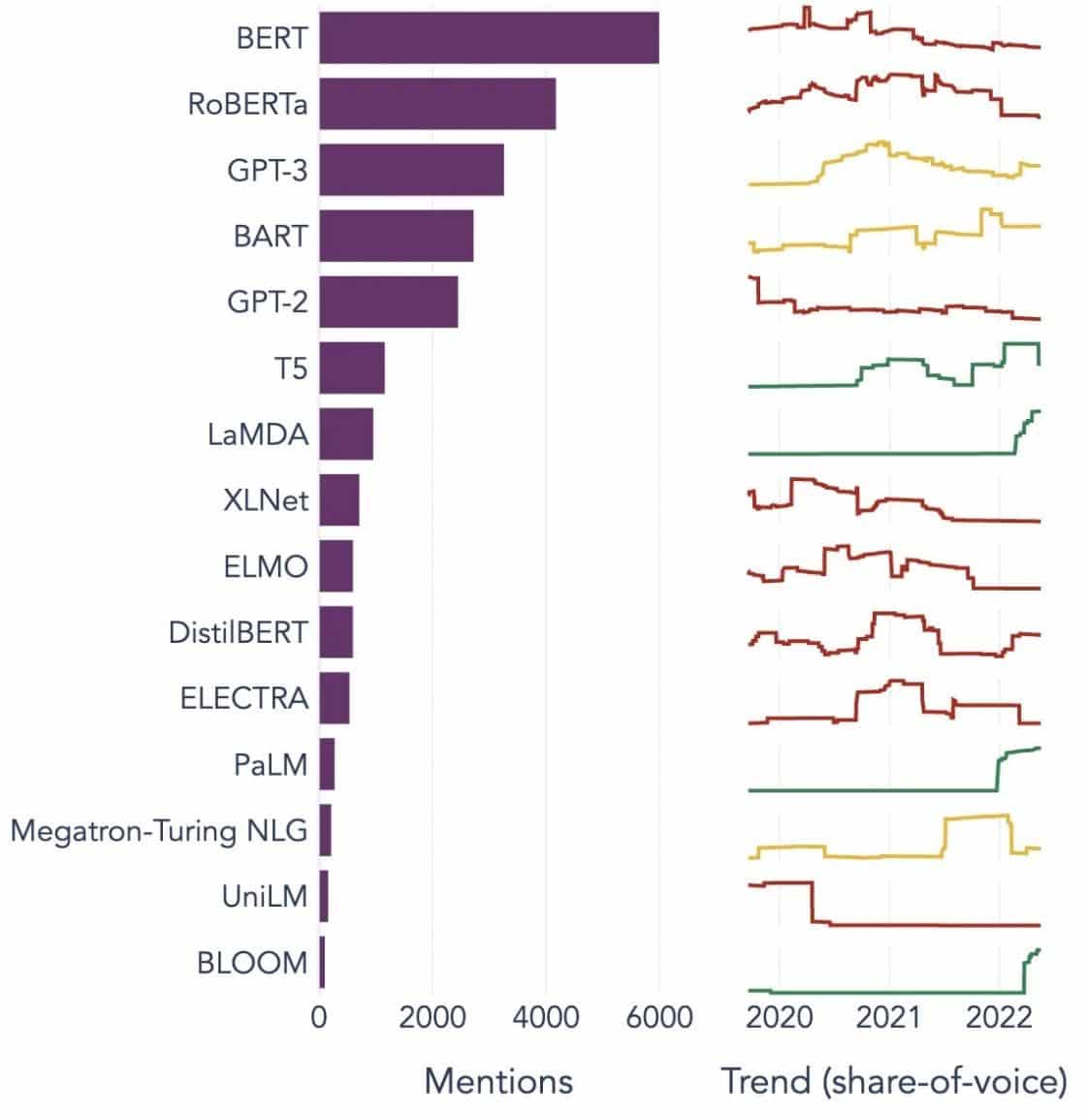
Image Source: Mot datavitenskap
Hvordan trenes LLM-modeller?
Å trene store språkmodeller (LLMs) er en bragd som involverer flere avgjørende trinn. Her er en forenklet, trinnvis oversikt over prosessen:
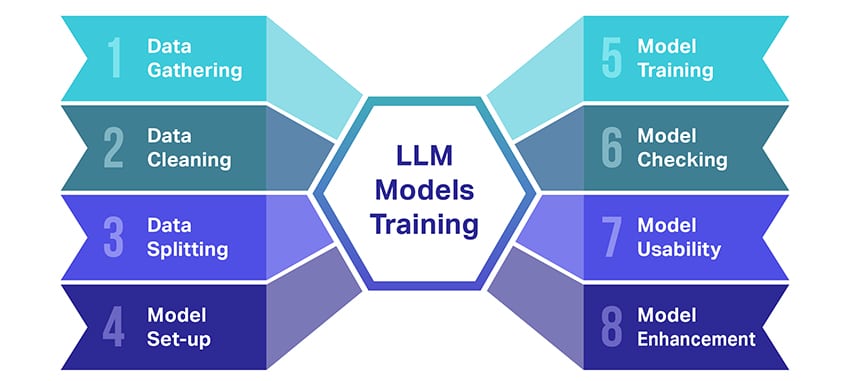
- Innsamling av tekstdata: Trening av en LLM starter med innsamling av en enorm mengde tekstdata. Disse dataene kan komme fra bøker, nettsteder, artikler eller sosiale medieplattformer. Målet er å fange det rike mangfoldet av menneskelig språk.
- Rydd opp i data: Råtekstdataene blir deretter ryddet opp i en prosess som kalles forbehandling. Dette inkluderer oppgaver som å fjerne uønskede tegn, bryte ned teksten i mindre deler kalt tokens, og få det hele til et format modellen kan jobbe med.
- Splitting av data: Deretter deles de rene dataene i to sett. Ett sett, treningsdataene, vil bli brukt til å trene modellen. Det andre settet, valideringsdataene, vil bli brukt senere for å teste modellens ytelse.
- Sette opp modellen: Strukturen til LLM, kjent som arkitekturen, blir deretter definert. Dette innebærer å velge type nevrale nettverk og bestemme ulike parametere, for eksempel antall lag og skjulte enheter i nettverket.
- Trening av modellen: Selve treningen begynner nå. LLM-modellen lærer ved å se på treningsdataene, lage spådommer basert på det den har lært så langt, og deretter justere de interne parameterne for å redusere forskjellen mellom spådommene og de faktiske dataene.
- Sjekker modellen: LLM-modellens læring kontrolleres ved hjelp av valideringsdataene. Dette hjelper deg med å se hvor godt modellen presterer og å finjustere modellens innstillinger for bedre ytelse.
- Bruk av modellen: Etter opplæring og evaluering er LLM-modellen klar til bruk. Den kan nå integreres i applikasjoner eller systemer der den vil generere tekst basert på nye input den er gitt.
- Forbedre modellen: Endelig er det alltid rom for forbedring. LLM-modellen kan foredles ytterligere over tid, ved å bruke oppdaterte data eller justere innstillinger basert på tilbakemelding og bruk i den virkelige verden.
Husk at denne prosessen krever betydelige beregningsressurser, for eksempel kraftige prosesseringsenheter og stor lagringsplass, samt spesialisert kunnskap innen maskinlæring. Det er derfor det vanligvis gjøres av dedikerte forskningsorganisasjoner eller selskaper med tilgang til nødvendig infrastruktur og kompetanse.
Er LLM avhengig av veiledet eller uovervåket læring?
Store språkmodeller trenes vanligvis ved hjelp av en metode som kalles supervised learning. Enkelt sagt betyr dette at de lærer av eksempler som viser dem de riktige svarene.
 Tenk deg at du lærer et barn ord ved å vise dem bilder. Du viser dem et bilde av en katt og sier «katt», og de lærer å assosiere det bildet med ordet. Det er slik veiledet læring fungerer. Modellen får mye tekst («bildene») og de tilsvarende utgangene («ordene»), og den lærer å matche dem.
Tenk deg at du lærer et barn ord ved å vise dem bilder. Du viser dem et bilde av en katt og sier «katt», og de lærer å assosiere det bildet med ordet. Det er slik veiledet læring fungerer. Modellen får mye tekst («bildene») og de tilsvarende utgangene («ordene»), og den lærer å matche dem.
Så hvis du gir en LLM en setning, prøver den å forutsi neste ord eller setning basert på hva den har lært fra eksemplene. På denne måten lærer den hvordan den genererer tekst som gir mening og passer konteksten.
Når det er sagt, noen ganger bruker LLM-er også litt uovervåket læring. Dette er som å la barnet utforske et rom fullt av forskjellige leker og lære om dem på egen hånd. Modellen ser på umerkede data, læringsmønstre og strukturer uten å bli fortalt de "riktige" svarene.
Overvåket læring bruker data som er merket med innganger og utganger, i motsetning til uovervåket læring, som ikke bruker merkede utdata.
I et nøtteskall trenes LLM-er hovedsakelig ved hjelp av overvåket læring, men de kan også bruke uovervåket læring for å forbedre sine evner, for eksempel for utforskende analyse og dimensjonalitetsreduksjon.
Hva er datavolumet (i GB) som er nødvendig for å trene opp en stor språkmodell?
En verden av muligheter for taledatagjenkjenning og taleapplikasjoner er enorm, og de brukes i flere bransjer for en mengde applikasjoner.
Å trene en stor språkmodell er ikke en prosess som passer alle, spesielt når det kommer til dataene som trengs. Det kommer an på en haug med ting:
- Modelldesignet.
- Hvilken jobb må den gjøre?
- Datatypen du bruker.
- Hvor godt vil du at den skal prestere?
Når det er sagt, krever opplæring av LLM-er vanligvis en enorm mengde tekstdata. Men hvor massive snakker vi om? Vel, tenk langt utover gigabyte (GB). Vi ser vanligvis på terabyte (TB) eller til og med petabyte (PB) med data.
Tenk på GPT-3, en av de største LLM-ene som finnes. Det trenes på 570 GB tekstdata. Mindre LLM-er trenger kanskje mindre – kanskje 10–20 GB eller til og med 1 GB gigabyte – men det er fortsatt mye.

Men det handler ikke bare om størrelsen på dataene. Kvalitet er også viktig. Dataene må være rene og varierte for å hjelpe modellen å lære effektivt. Og du kan ikke glemme andre viktige brikker i puslespillet, som datakraften du trenger, algoritmene du bruker til trening og maskinvareoppsettet du har. Alle disse faktorene spiller en stor rolle i opplæringen av en LLM.
Fremveksten av store språkmodeller: hvorfor de betyr noe
LLM-er er ikke lenger bare et konsept eller et eksperiment. De spiller i økende grad en kritisk rolle i vårt digitale landskap. Men hvorfor skjer dette? Hva gjør disse LLM-ene så viktige? La oss fordype oss i noen nøkkelfaktorer.
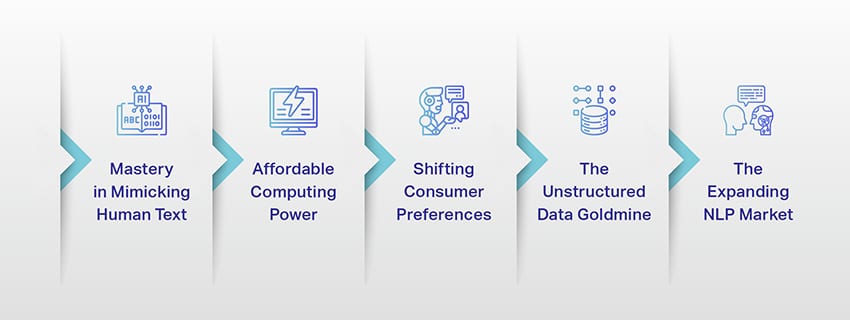
Mestring i å etterligne menneskelig tekst
LLM-er har endret måten vi håndterer språkbaserte oppgaver på. Bygget ved hjelp av robuste maskinlæringsalgoritmer, er disse modellene utstyrt med evnen til å forstå nyansene i menneskelig språk, inkludert kontekst, følelser og til og med sarkasme, til en viss grad. Denne evnen til å etterligne menneskelig språk er ikke bare en nyhet, den har betydelige implikasjoner.
LLMs avanserte tekstgenereringsevner kan forbedre alt fra innholdsskaping til kundeserviceinteraksjoner.
Tenk deg å kunne stille en digital assistent et komplekst spørsmål og få et svar som ikke bare gir mening, men som også er sammenhengende, relevant og levert i en samtaletone. Det er det LLM-er muliggjør. De gir næring til en mer intuitiv og engasjerende menneske-maskin-interaksjon, beriker brukeropplevelser og demokratiserer tilgang til informasjon.
Rimelig datakraft
Fremveksten av LLM-er ville ikke vært mulig uten parallell utvikling innen databehandling. Mer spesifikt har demokratiseringen av beregningsressursene spilt en betydelig rolle i utviklingen og innføringen av LLM-er.
Skybaserte plattformer tilbyr enestående tilgang til dataressurser med høy ytelse. På denne måten kan selv småskalaorganisasjoner og uavhengige forskere trene opp sofistikerte maskinlæringsmodeller.
Dessuten har forbedringer i prosesseringsenheter (som GPUer og TPUer), kombinert med fremveksten av distribuert databehandling, gjort det mulig å trene modeller med milliarder av parametere. Denne økte tilgjengeligheten til datakraft muliggjør vekst og suksess for LLM-er, og fører til mer innovasjon og applikasjoner på feltet.
Skifte forbrukerpreferanser
Forbrukere i dag vil ikke bare ha svar; de ønsker engasjerende og relaterbare interaksjoner. Etter hvert som flere mennesker vokser opp med digital teknologi, er det tydelig at behovet for teknologi som føles mer naturlig og menneskelignende øker. LLM gir en uovertruffen mulighet til å møte disse forventningene. Ved å generere menneskelignende tekst kan disse modellene skape engasjerende og dynamiske digitale opplevelser, som kan øke brukertilfredshet og lojalitet. Enten det er AI-chatbots som gir kundeservice eller taleassistenter som gir nyhetsoppdateringer, innleder LLM-er en æra med AI som forstår oss bedre.
Den ustrukturerte datagullgruven
Ustrukturerte data, som e-poster, innlegg på sosiale medier og kundeanmeldelser, er en skattekiste av innsikt. Det er anslått at over 80% av bedriftsdata er ustrukturert og vokser med en hastighet på 55% per år. Disse dataene er en gullgruve for bedrifter hvis de utnyttes på riktig måte.
LLM-er kommer inn i bildet her, med deres evne til å behandle og gi mening om slike data i stor skala. De kan håndtere oppgaver som sentimentanalyse, tekstklassifisering, informasjonsutvinning og mer, og gir dermed verdifull innsikt.
Enten det er å identifisere trender fra innlegg på sosiale medier eller å måle kundesentiment fra anmeldelser, hjelper LLM-er bedrifter med å navigere i den store mengden ustrukturerte data og ta datadrevne beslutninger.
Det ekspanderende NLP-markedet
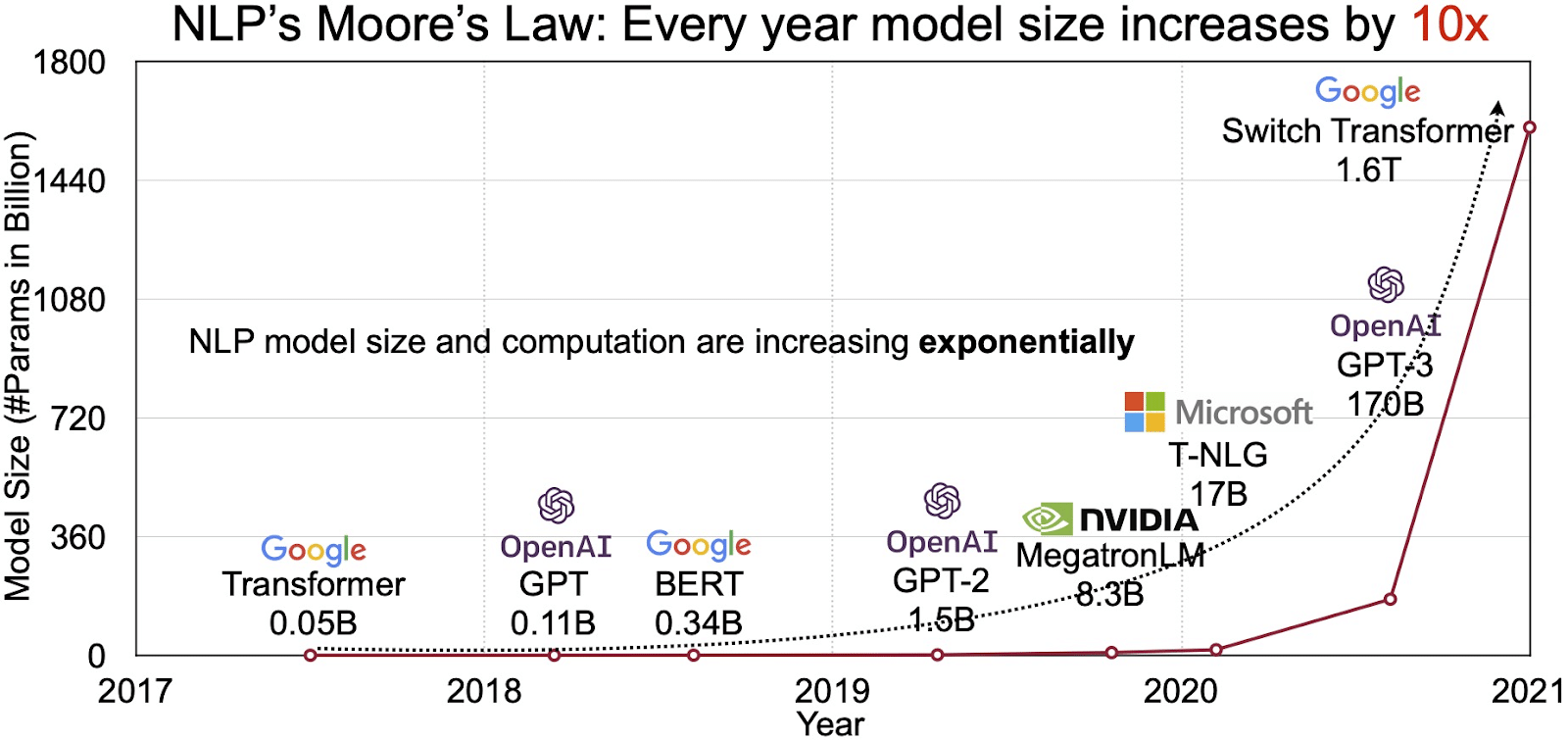
Potensialet til LLM-er gjenspeiles i det raskt voksende markedet for naturlig språkbehandling (NLP). Analytikere anslår at NLP-markedet kan utvides fra 11 milliarder dollar i 2020 til over 35 milliarder dollar innen 2026. Men det er ikke bare markedsstørrelsen som utvides. Selve modellene vokser også, både i fysisk størrelse og i antall parametere de håndterer. Utviklingen av LLM-er gjennom årene, som vist i figuren nedenfor (bildekilde: lenke), understreker deres økende kompleksitet og kapasitet.
Populære brukstilfeller av store språkmodeller
Her er noen av de beste og mest utbredte brukstilfellene av LLM:
- Generering av naturlig språktekst: Store språkmodeller (LLMs) kombinerer kraften til kunstig intelligens og datalingvistikk for autonomt å produsere tekster på naturlig språk. De kan imøtekomme ulike brukerbehov, for eksempel skrive artikler, lage sanger eller delta i samtaler med brukere.
- Oversettelse gjennom maskiner: LLM-er kan effektivt brukes til å oversette tekst mellom et hvilket som helst par språk. Disse modellene utnytter dyplæringsalgoritmer som tilbakevendende nevrale nettverk for å forstå den språklige strukturen til både kilde- og målspråk, og dermed lette oversettelsen av kildeteksten til ønsket språk.
- Lage originalt innhold: LLM-er har åpnet muligheter for maskiner for å generere sammenhengende og logisk innhold. Dette innholdet kan brukes til å lage blogginnlegg, artikler og andre typer innhold. Modellene utnytter sin dype læringsopplevelse for å formatere og strukturere innholdet på en ny og brukervennlig måte.
- Analyse av følelser: En spennende anvendelse av store språkmodeller er sentimentanalyse. I dette trenes modellen til å gjenkjenne og kategorisere emosjonelle tilstander og følelser som er tilstede i den kommenterte teksten. Programvaren kan identifisere følelser som positivitet, negativitet, nøytralitet og andre intrikate følelser. Dette kan gi verdifull innsikt i tilbakemeldinger fra kunder og synspunkter om ulike produkter og tjenester.
- Forstå, oppsummere og klassifisere tekst: LLM-er etablerer en levedyktig struktur for AI-programvare for å tolke teksten og dens kontekst. Ved å instruere modellen til å forstå og granske enorme mengder data, gjør LLM-er det mulig for AI-modeller å forstå, oppsummere og til og med kategorisere tekst i forskjellige former og mønstre.
- Svare på spørsmål: Store språkmodeller utstyrer QA-systemer (Question Answering) med muligheten til nøyaktig å oppfatte og svare på en brukers naturlige språkspørring. Populære eksempler på denne brukssaken inkluderer ChatGPT og BERT, som undersøker konteksten til en spørring og siler gjennom en stor samling tekster for å levere relevante svar på brukerspørsmål.

Part-of-Speech (POS)-tagging
Ord i setninger er merket med sin grammatiske funksjon, slik som verb, substantiv, adjektiver, osv. Denne prosessen hjelper modellen med å forstå grammatikken og koblingene mellom ord.

Navngitt entitetsgjenkjenning (NER)
Navngitte enheter som organisasjoner, steder og personer i en setning er merket. Denne øvelsen hjelper modellen med å tolke den semantiske betydningen av ord og uttrykk og gir mer presise svar.

Sentiment Analyse
Tekstdata tildeles sentimentetiketter som positiv, nøytral eller negativ, og hjelper modellen med å forstå den emosjonelle undertonen til setninger. Den er spesielt nyttig for å svare på spørsmål som involverer følelser og meninger.
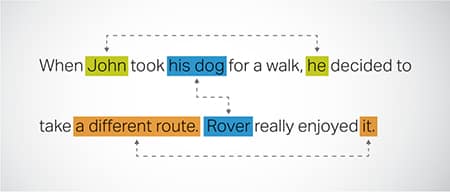
Coreference Resolution
Identifisere og løse tilfeller der samme enhet refereres til i forskjellige deler av en tekst. Dette trinnet hjelper modellen å forstå konteksten til setningen, og fører dermed til sammenhengende svar.
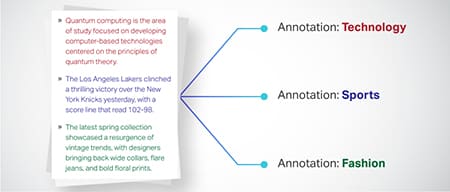
Tekstklassifisering
Tekstdata er kategorisert i forhåndsdefinerte grupper som produktanmeldelser eller nyhetsartikler. Dette hjelper modellen med å skjelne sjangeren eller emnet for teksten, og genererer mer relevante svar.
Shaips tilbud
Shaip tilbyr et bredt spekter av tjenester for å hjelpe organisasjoner med å administrere, analysere og få mest mulig ut av dataene deres.
Data Web-skraping
En nøkkeltjeneste som tilbys av Shaip er dataskraping. Dette innebærer utvinning av data fra domenespesifikke URL-er. Ved å bruke automatiserte verktøy og teknikker kan Shaip raskt og effektivt skrape store mengder data fra ulike nettsteder, produktmanualer, teknisk dokumentasjon, nettfora, nettanmeldelser, kundeservicedata, industriregulerende dokumenter osv. Denne prosessen kan være uvurderlig for bedrifter når samle relevante og spesifikke data fra en rekke kilder.

Maskinoversettelse
Utvikle modeller ved å bruke omfattende flerspråklige datasett sammen med tilsvarende transkripsjoner for å oversette tekst på tvers av forskjellige språk. Denne prosessen hjelper til med å demontere språklige hindringer og fremmer tilgjengeligheten til informasjon.
Taksonomi utvinning og opprettelse
Shaip kan hjelpe med taksonomiutvinning og opprettelse. Dette innebærer å klassifisere og kategorisere data i et strukturert format som gjenspeiler relasjonene mellom ulike datapunkter. Dette kan være spesielt nyttig for bedrifter når de skal organisere dataene sine, noe som gjør dem mer tilgjengelige og enklere å analysere. For eksempel, i en e-handelsbedrift, kan produktdata kategoriseres basert på produkttype, merke, pris osv., noe som gjør det enklere for kunder å navigere i produktkatalogen.
Datainnsamling
Datainnsamlingstjenestene våre gir kritiske virkelige eller syntetiske data som er nødvendige for å trene generative AI-algoritmer og forbedre nøyaktigheten og effektiviteten til modellene dine. Dataene er objektive, etisk og ansvarlig hentet, samtidig som personvern og sikkerhet i tankene.

Spørsmål og svar
Spørsmålssvar (QA) er et underfelt av naturlig språkbehandling med fokus på automatisk besvarelse av spørsmål på menneskelig språk. QA-systemer er trent på omfattende tekst og kode, som gjør dem i stand til å håndtere ulike typer spørsmål, inkludert fakta-, definisjons- og meningsbaserte. Domenekunnskap er avgjørende for å utvikle QA-modeller skreddersydd for spesifikke felt som kundestøtte, helsetjenester eller forsyningskjede. Generative QA-tilnærminger lar imidlertid modeller generere tekst uten domenekunnskap, kun avhengig av kontekst.
Teamet vårt av spesialister kan omhyggelig studere omfattende dokumenter eller manualer for å generere spørsmål-svar-par, noe som letter etableringen av generativ AI for bedrifter. Denne tilnærmingen kan effektivt takle brukerhenvendelser ved å hente ut relevant informasjon fra et omfattende korpus. Våre sertifiserte eksperter sørger for produksjon av kvalitetsspørsmål og svar som spenner over ulike emner og domener.

Tekstoppsummering
Spesialistene våre er i stand til å destillere omfattende samtaler eller lange dialoger, og levere kortfattede og innsiktsfulle sammendrag fra omfattende tekstdata.

Tekstgenerering
Tren modeller ved å bruke et bredt datasett med tekst i forskjellige stiler, som nyhetsartikler, skjønnlitteratur og poesi. Disse modellene kan deretter generere ulike typer innhold, inkludert nyhetsartikler, blogginnlegg eller innlegg på sosiale medier, og tilbyr en kostnadseffektiv og tidsbesparende løsning for innholdsskaping.
Talegjenkjenning
Utvikle modeller som er i stand til å forstå talespråk for ulike applikasjoner. Dette inkluderer stemmeaktiverte assistenter, dikteringsprogramvare og sanntidsoversettelsesverktøy. Prosessen innebærer å bruke et omfattende datasett som består av lydopptak av talespråk, sammen med tilhørende transkripsjoner.

Produktanbefalinger
Utvikle modeller ved å bruke omfattende datasett med kundekjøpshistorier, inkludert etiketter som viser til produktene kundene er tilbøyelige til å kjøpe. Målet er å gi presise forslag til kundene, og dermed øke salget og øke kundetilfredsheten.
Bildeteksting
Revolusjoner din bildetolkningsprosess med vår toppmoderne, AI-drevne bildeteksttjeneste. Vi tilfører vitalitet til bilder ved å produsere nøyaktige og kontekstuelt meningsfulle beskrivelser. Dette baner vei for nyskapende engasjement og interaksjonsmuligheter med ditt visuelle innhold for publikum.

Opplæring av tekst-til-tale-tjenester
Vi tilbyr et omfattende datasett som består av lydopptak av menneskelig tale, ideelt for opplæring av AI-modeller. Disse modellene er i stand til å generere naturlige og engasjerende stemmer for applikasjonene dine, og dermed levere en særegen og oppslukende lydopplevelse for brukerne dine.



