









- Bruk sak: Objektgjenkjenningsmodell
- Format: videoer
- Volum: 5,000 +
- merknad: Nei

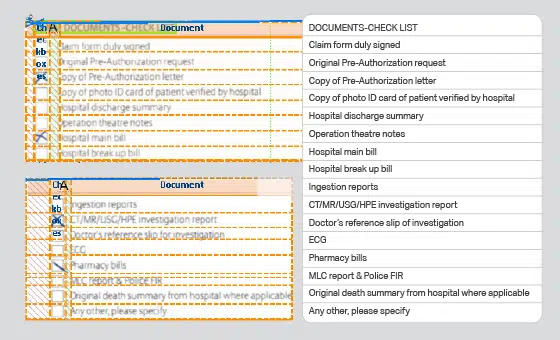
- Bruk sak: Dok. Anerkjennelsesmodell
- Format: Bilder
- Volum: 15,900 +
- merknad: Nei
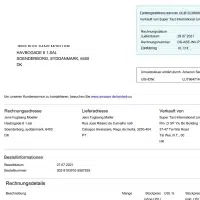
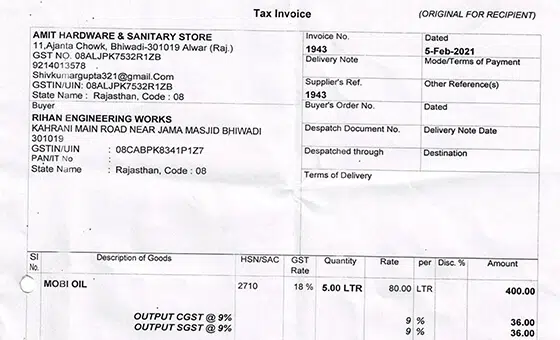
- Bruk sak: Fakturagjenkjenning. Modell
- Format: Bilder
- Volum: 45,000 +
- merknad: Nei

- Bruk sak: nr. Plategjenkjenning
- Format: Bilder
- Volum: 3,500 +
- merknad: Nei

- Bruk sak: OCR-modell
- Format: Bilder
- Volum: 90,000 +
- merknad: Ja

- Bruk sak: Flerspråklig OCR-modell
- Format: Bilder
- Volum: 23,500 +
- merknad: Ja
- Bruk sak: Objektdeteksjonsmodell
- Format: Bilder
- Volum: 11,500 +
- merknad: Nei

- Bruk sak: AI-modeller for kvittering
- Format: Bilder
- Volum: 75,000 +
- merknad: Nei

porsjoner
Dedikerte og trente team:
- 30,000 XNUMX+ samarbeidspartnere for datainnsamling, merking og kvalitetssikring
- Godkjent prosjektlederteam
- Erfarent produktutviklingsteam
- Talentpool-innkjøps- og onboarding-team

Prosess
Høyeste prosesseffektivitet er sikret med:
- Robust 6 Sigma Stage-Gate-prosess
- Et dedikert team av 6 Sigma svarte belter – nøkkelprosesseiere og overholdelse av kvalitet
- Kontinuerlig forbedring og tilbakemeldingssløyfe

Plattform
Den patenterte plattformen tilbyr fordeler:
- Nettbasert ende-til-ende-plattform
- Upåklagelig kvalitet
- Raskere TAT
- Sømløs levering



Å lage klinisk NLP er en kritisk oppgave som krever enorm domenekompetanse for å løse. Jeg kan tydelig se at du er flere år foran Google på dette området. Jeg vil jobbe med deg og skalere deg.
Google, Inc. Regissør
Ingeniørteamet mitt jobbet med Shaips team i mer enn 2 år under utviklingen av tale -APIer for helsetjenester. Vi har blitt imponert over arbeidet deres med helsespesifikk NLP og hva de kan oppnå med komplekse datasett.
Google, Inc. Sjef for ingeniørfag