



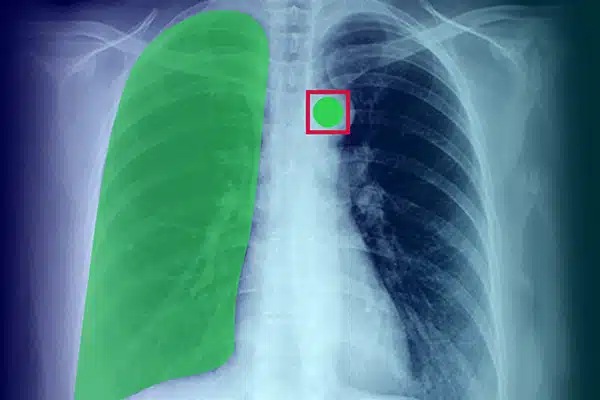
Bildekommentar
Forbedre medisinsk AI ved å kommentere visuelle data fra røntgenbilder, CT-skanninger og MR-er. Sørg for at AI-modeller yter utmerket i diagnostikk og behandling, veiledet av merking av ekspertdata. Få bedre pasientresultater med overlegen bildeinnsikt.
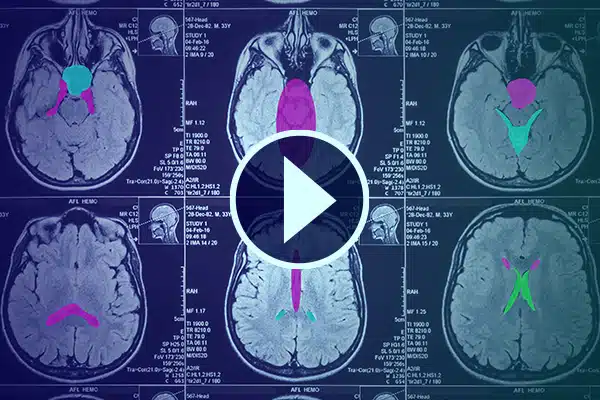
Videokommentar
Avanser AI i helsevesenet med detaljert videokommentar. Skjerp AI-læring med klassifiseringer og segmenteringer i medisinske opptak. Forbedre din kirurgiske AI og pasientovervåking for forbedret helsetjenester og diagnostikk.
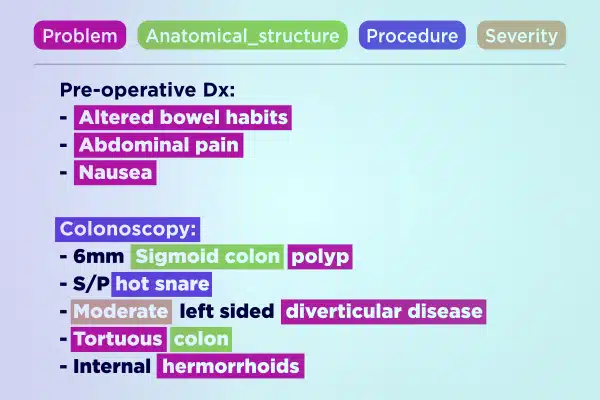
Tekstkommentar
Strømlinjeform medisinsk AI-utvikling med ekspertkommenterte tekstdata. Analyser og berik raskt store tekstvolumer, fra håndskrevne notater til forsikringsrapporter. Sikre nøyaktig og handlingskraftig innsikt for fremskritt i helsevesenet.

Lydkommentar
Utnytt NLP-ekspertise for å kommentere og merke medisinske lyddata nøyaktig. Lag stemmeassisterte systemer for sømløs klinisk drift og integrer AI i ulike stemmeaktiverte helseprodukter. Forbedre diagnostisk presisjon med ekspertlyddatakurering.

Medisinsk koding
Strømlinjeform medisinsk dokumentasjon ved å konvertere den til universelle koder med medisinsk AI-koding. Sikre nøyaktighet, forbedre faktureringseffektiviteten og støtte sømløs levering av helsetjenester med banebrytende AI-hjelp i medisinsk journalkoding.

Fase 1: Teknisk domeneekspertise (Forstå omfang og retningslinjer for kommentarer)

Fase 2: Opplæring av passende ressurser for prosjektet

Fase 3: Tilbakemeldingssyklus og kvalitetssikring av de kommenterte dokumentene
Radiologi
Vår røntgenbildeannoteringstjeneste skjerper AI-diagnostikk og inkluderer et ekstra lag med ekspertise. Hver røntgen-, MR- og CT-skanning er omhyggelig merket og gjennomgått av en sakkyndig. Dette ekstra trinnet i trening og gjennomgang øker AIs evne til å oppdage abnormiteter og sykdommer. Det øker nøyaktigheten før levering til våre kunder.

Kardiologi
Vår kardiologifokuserte bildekommentar gjør AI-diagnostikk skarpere. Vi henter inn kardiologieksperter som merker komplekse hjerterelaterte bilder og trener våre AI-modeller. Før vi sender data til kunder, gjennomgår disse spesialistene hvert bilde for å sikre førsteklasses nøyaktighet. Denne prosessen gjør AI i stand til å oppdage hjertesykdommer mer presist.
Tannbehandling
Vår bildekommentartjeneste i odontologi merker tannbilder for å forbedre AI-diagnoseverktøy. Ved å nøyaktig identifisere tannråte, problemer med justering og andre tanntilstander, styrker våre SMB-er AI til å forbedre pasientresultater og støtte tannleger i presis behandlingsplanlegging og tidlig oppdagelse.


















porsjoner
Dedikerte og trente team:
- 30,000+ samarbeidspartnere for dataskaping, merking og kvalitetssikring
- Godkjent prosjektlederteam
- Erfarent produktutviklingsteam
- Talentpool-innkjøps- og onboarding-team

Prosess
Høyeste prosesseffektivitet er sikret med:
- Robust 6 Sigma Stage-Gate-prosess
- Et dedikert team av 6 Sigma svarte belter – nøkkelprosesseiere og overholdelse av kvalitet
- Kontinuerlig forbedring og tilbakemeldingssløyfe

Plattform
Den patenterte plattformen tilbyr fordeler:
- Nettbasert ende-til-ende-plattform
- Upåklagelig kvalitet
- Raskere TAT
- Sømløs levering



