Introduksjon
 Kunstig intelligens handler om å bruke maskiner for å heve livet og livsstilen til mennesker ved å gjøre deres hverdagslige liv interessante og overflødige oppgaver enkle. AI skal aldri være en dominerende kraft, men en komplementær kraft som jobber sammen med mennesker for å løse det usannsynlige og bane vei for kollektiv evolusjon.
Kunstig intelligens handler om å bruke maskiner for å heve livet og livsstilen til mennesker ved å gjøre deres hverdagslige liv interessante og overflødige oppgaver enkle. AI skal aldri være en dominerende kraft, men en komplementær kraft som jobber sammen med mennesker for å løse det usannsynlige og bane vei for kollektiv evolusjon.
Per nå tråkker vi på rett vei med betydelige gjennombrudd på tvers av bransjer ved hjelp av AI. Hvis du for eksempel tar helsetjenester, hjelper AI-systemer ledsaget av maskinlæringsmodeller eksperter til å forstå kreft bedre og komme opp med behandlinger for den. Nevrologiske lidelser og bekymringer som PTSD blir behandlet ved hjelp av AI. Vaksiner utvikles i raske takter takket være AI-drevne kliniske studier og simuleringer.
Ikke bare helsevesenet, hver eneste bransje eller segment som AI berører blir revolusjonert. Autonome kjøretøy, smarte nærbutikker, wearables som FitBit og til og med smarttelefonkameraene våre er i stand til å ta bedre bilder av ansiktene våre med AI.
Takket være innovasjonene som skjer i AI-området, kommer bedrifter inn i spekteret med ulike brukstilfeller og løsninger. På grunn av dette forventes det globale AI-markedet å nå en markedsverdi på rundt 267 milliarder dollar innen utgangen av 2027. Dessuten implementerer rundt 37 % av virksomhetene der ute AI-løsninger i sine prosesser og produkter.
Mer interessant er det at nesten 77 % av produktene og tjenestene vi bruker i dag er drevet av AI. Med teknologikonseptet som øker betydelig på tvers av vertikaler, hvordan klarer bedrifter å gjøre det umulig med AI?

 Hvordan forutsier enheter så enkle som en klokke hjerteinfarkt hos mennesker nøyaktig? Hvordan er det mulig at biler og biler som alltid har krevd en sjåfør, plutselig kjører mindre på veiene?
Hvordan forutsier enheter så enkle som en klokke hjerteinfarkt hos mennesker nøyaktig? Hvordan er det mulig at biler og biler som alltid har krevd en sjåfør, plutselig kjører mindre på veiene?
Hvordan får chatboter oss til å tro at vi snakker med et annet menneske på den andre siden?
Hvis du observerer svaret på hvert spørsmål, koker det ned til bare ett element – DATA. Data ligger i sentrum av alle AI-spesifikke operasjoner og prosesser. Det er data som hjelper maskiner å forstå konsepter, prosessinnganger og levere nøyaktige resultater.
Alle de store AI-løsningene som finnes der ute, er alle produkter av en avgjørende prosess vi kaller datainnsamling eller datainnsamling eller AI-treningsdata.
Denne omfattende veiledningen handler om å hjelpe deg å forstå hva det er og hvorfor det er viktig.
Hva er AI-datainnsamling?
Maskiner har ikke et eget sinn. Fraværet av dette abstrakte konseptet gjør dem blottet for meninger, fakta og evner som resonnement, erkjennelse og mer. De er bare faste bokser eller enheter som opptar plass. For å gjøre dem om til kraftige medier trenger du algoritmer og enda viktigere data.
 Algoritmene som utvikles trenger noe å jobbe med og bearbeide og at noe er data som er relevante, kontekstuelle og nyere. Prosessen med å samle inn slike data for maskiner for å tjene deres tiltenkte formål kalles AI-datainnsamling.
Algoritmene som utvikles trenger noe å jobbe med og bearbeide og at noe er data som er relevante, kontekstuelle og nyere. Prosessen med å samle inn slike data for maskiner for å tjene deres tiltenkte formål kalles AI-datainnsamling.
Hvert eneste AI-aktiverte produkt eller løsning vi bruker i dag og resultatene de tilbyr stammer fra år med opplæring, utvikling og optimalisering. Fra enheter som tilbyr navigasjonsruter til de komplekse systemene som forutsier utstyrsfeil dager i forveien, har hver enkelt enhet gått gjennom år med AI-trening for å kunne levere nøyaktige resultater.
AI-datainnsamling er det foreløpige trinnet i prosessen med AI-utvikling som helt fra begynnelsen bestemmer hvor effektivt og effektivt et AI-system vil være. Det er prosessen med å hente inn relevante datasett fra en myriade av kilder som vil hjelpe AI-modeller med å behandle detaljer bedre og gi meningsfulle resultater.




Hvordan samle inn data for en maskinlæring?
 Det er her ting begynner å bli litt vanskelige. Fra begynnelsen ser det ut til at du har en løsning på et reell problem i tankene, du vet at AI ville være den ideelle måten å gå frem på, og du har utviklet modellene dine. Men nå er du i den avgjørende fasen hvor du må starte AI-treningsprosessene dine. Du trenger rikelig med AI-treningsdata for å få modellene dine til å lære konsepter og levere resultater. Du trenger også valideringsdata for å teste resultatene dine og optimalisere algoritmene dine.
Det er her ting begynner å bli litt vanskelige. Fra begynnelsen ser det ut til at du har en løsning på et reell problem i tankene, du vet at AI ville være den ideelle måten å gå frem på, og du har utviklet modellene dine. Men nå er du i den avgjørende fasen hvor du må starte AI-treningsprosessene dine. Du trenger rikelig med AI-treningsdata for å få modellene dine til å lære konsepter og levere resultater. Du trenger også valideringsdata for å teste resultatene dine og optimalisere algoritmene dine.
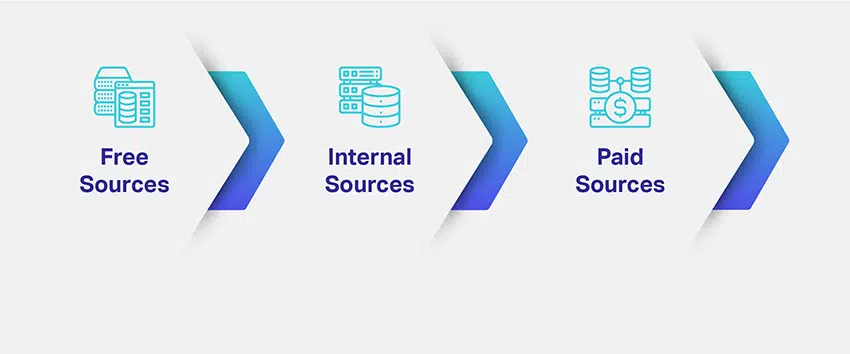
Så hvordan henter du dataene dine? Hvilke data trenger du og hvor mye av dem? Hva er de mange kildene for å hente relevante data?
Bedrifter vurderer nisjen og formålet med ML-modellene deres og kartlegger potensielle måter å hente relevante datasett på. Å definere datatypen som trengs løser en stor del av bekymringen din om datainnhenting. For å gi deg en bedre ide finnes det forskjellige kanaler, veier, kilder eller medier for datainnsamling:
Hvordan påvirker dårlige data AI-ambisjonene dine?
Vi har listet opp de tre vanligste dataressursene av den grunn at du vil ha en ide om hvordan du kan nærme deg datainnsamling og innhenting. Men på dette tidspunktet blir det viktig å også forstå at avgjørelsen din alltid kan avgjøre skjebnen til AI-løsningen din.
I likhet med hvordan høykvalitets AI-treningsdata kan hjelpe modellen din til å levere nøyaktige og rettidige resultater, kan dårlige treningsdata også bryte AI-modellene dine, forvride resultater, introdusere skjevheter og gi andre uønskede konsekvenser.
Men hvorfor skjer dette? Er det ikke meningen at noen data skal trene og optimalisere AI-modellen din? Ærlig talt, nei. La oss forstå dette nærmere.
Dårlige data – hva er det?
 Dårlige data er alle data som er irrelevante, feilaktige, ufullstendige eller partiske. Takket være dårlig definerte datainnsamlingsstrategier har de fleste dataforskere og annoteringseksperter er tvunget til å jobbe med dårlige data.
Dårlige data er alle data som er irrelevante, feilaktige, ufullstendige eller partiske. Takket være dårlig definerte datainnsamlingsstrategier har de fleste dataforskere og annoteringseksperter er tvunget til å jobbe med dårlige data.
Forskjellen mellom ustrukturerte og dårlige data er at innsikt i ustrukturerte data er over alt. Men i hovedsak kan de være nyttige uansett. Ved å bruke ekstra tid vil dataforskere fortsatt kunne trekke ut relevant informasjon fra ustrukturerte datasett. Det er imidlertid ikke tilfelle med dårlige data. Disse datasettene inneholder ingen/begrenset innsikt eller informasjon som er verdifull eller relevant for AI-prosjektet ditt eller dets opplæringsformål.
Så når du henter datasettene dine fra gratis ressurser eller har løst etablerte interne datakontaktpunkter, er sjansen stor for at du vil laste ned eller generere dårlige data. Når forskerne jobber med dårlige data, kaster du ikke bare bort menneskelige timer, men presser også på lanseringen av produktet ditt.
Hvis du fortsatt er usikker på hva dårlige data kan gjøre med ambisjonene dine, her er en rask liste:
- Du bruker utallige timer på å skaffe de dårlige dataene og kaster bort timer, krefter og penger på ressurser.
- Dårlige data kan føre til juridiske problemer, hvis de ikke blir lagt merke til, og kan redusere effektiviteten til AI-en din
modeller. - Når du tar produktet trent på dårlige data live, påvirker det brukeropplevelsen
- Dårlige data kan gjøre resultater og slutninger partiske, noe som kan gi ytterligere tilbakeslag.
Så hvis du lurer på om det finnes en løsning på dette, er det faktisk det.
AI Training Dataleverandører til unnsetning
 En av de grunnleggende løsningene er å gå for en dataleverandør (betalte kilder). Leverandører av AI-opplæringsdata sikrer at det du mottar er nøyaktig og relevant, og at du har datasett levert til deg i en strukturert form. Du trenger ikke å være involvert i bryet med å flytte fra portal til portal på jakt etter datasett.
En av de grunnleggende løsningene er å gå for en dataleverandør (betalte kilder). Leverandører av AI-opplæringsdata sikrer at det du mottar er nøyaktig og relevant, og at du har datasett levert til deg i en strukturert form. Du trenger ikke å være involvert i bryet med å flytte fra portal til portal på jakt etter datasett.
Alt du trenger å gjøre er å ta inn dataene og trene AI-modellene dine for perfeksjon. Når det er sagt, er vi sikre på at ditt neste spørsmål handler om utgiftene forbundet med å samarbeide med dataleverandører. Vi forstår at noen av dere allerede jobber med et mentalt budsjett, og det er akkurat dit vi er på vei videre.
Faktorer du bør vurdere når du skal lage et effektivt budsjett for datainnsamlingsprosjektet ditt
AI-trening er en systematisk tilnærming, og det er derfor budsjettering blir en integrert del av det. Faktorer som avkastning, nøyaktighet av resultater, opplæringsmetoder og mer bør vurderes før du investerer en enorm sum penger i AI-utvikling. Mange prosjektledere eller bedriftseiere famler på dette stadiet. De tar forhastede beslutninger som fører til irreversible endringer i produktutviklingsprosessen, og til slutt tvinger dem til å bruke mer.
Imidlertid vil denne delen gi deg den rette innsikten. Når du setter deg ned for å jobbe med budsjettet for AI-trening, er tre ting eller faktorer uunngåelige.

La oss se på hver enkelt i detalj.
Mengden data du trenger
Vi har hele tiden sagt at effektiviteten og nøyaktigheten til AI-modellen din avhenger av hvor mye den er trent. Dette betyr at jo mer volumet av datasett, jo mer læring. Men dette er veldig vagt. For å sette et tall på denne oppfatningen publiserte Dimensional Research en rapport som avslørte at bedrifter trenger minimum 100,000 XNUMX prøvedatasett for å trene AI-modellene sine.
Med 100,000 100,000 datasett mener vi XNUMX XNUMX kvalitets- og relevante datasett. Disse datasettene bør ha alle de essensielle egenskapene, merknadene og innsiktene som kreves for at algoritmene og maskinlæringsmodellene dine skal kunne behandle informasjon og utføre tiltenkte oppgaver.
Med dette er en generell tommelfingerregel, la oss forstå at mengden av data du trenger også avhenger av en annen intrikat faktor som er din bedrifts brukssituasjon. Hva du har tenkt å gjøre med produktet eller løsningen avgjør også hvor mye data du trenger. For eksempel vil en bedrift som bygger en anbefalingsmotor ha andre datavolumkrav enn et selskap som bygger en chatbot.
Dataprisstrategi
Når du er ferdig med å fullføre hvor mye data du faktisk trenger, må du jobbe videre med en dataprisstrategi. Dette betyr på en enkel måte hvordan du vil betale for datasettene du anskaffer eller genererer.
Generelt er dette de konvensjonelle prisstrategiene som følges i markedet:
| Data-type | Pris strategi |
|---|---|
| Pris per enkelt bildefil | |
| Pris per sekund, minutt, time eller enkeltbilde | |
| Pris per sekund, et minutt eller time | |
| Pris per ord eller setning |
Men vent. Dette er igjen en tommelfingerregel. De faktiske kostnadene ved å anskaffe datasett avhenger også av faktorer som:
- Det unike markedssegmentet, demografi eller geografi der datasett må hentes fra
- Det kompliserte i brukssaken din
- Hvor mye data trenger du?
- Din tid til å markedsføre
- Eventuelle skreddersydde krav og mer
Hvis du observerer, vil du vite at kostnadene for å skaffe bulkmengder med bilder for AI-prosjektet ditt kan være mindre, men hvis du har for mange spesifikasjoner, kan prisene skyte opp.
Dine kildestrategier
Dette er vanskelig. Som du så, er det forskjellige måter å generere eller hente data for AI-modellene dine på. Sunn fornuft vil tilsi at gratis ressurser er de beste siden du kan laste ned nødvendige mengder datasett gratis uten noen komplikasjoner.
Akkurat nå ser det også ut til at betalte kilder er for dyre. Men det er her et lag med komplikasjoner blir lagt til. Når du henter datasett fra gratisressurser, bruker du ekstra tid og krefter på å rense datasettene dine, kompilere dem til ditt forretningsspesifikke format og deretter kommentere dem individuelt. Du pådrar deg driftskostnader i prosessen.
Med betalte kilder er betalingen engangsbetaling og du får også maskinklare datasett i hånden på det tidspunktet du trenger. Kostnadseffektiviteten er veldig subjektiv her. Hvis du føler at du har råd til å bruke tid på å kommentere gratis datasett, kan du budsjettere deretter. Og hvis du tror at konkurransen din er hard og med begrenset tid til å markedsføre, kan du skape en ringvirkning i markedet, du bør foretrekke betalte kilder.
Budsjettering handler om å bryte ned detaljene og tydelig definere hvert fragment. Disse tre faktorene bør tjene deg som et veikart for budsjetteringsprosessen for AI-trening i fremtiden.
Sparer du på utgifter med intern datainnsamling?
 Mens vi budsjetterte, undersøkte vi hvordan gratis ressurser tvinger deg til å bruke mer på lengre sikt. På det tidspunktet ville du automatisk ha lurt på kostnadseffektiviteten til den interne datainnsamlingsprosessen.
Mens vi budsjetterte, undersøkte vi hvordan gratis ressurser tvinger deg til å bruke mer på lengre sikt. På det tidspunktet ville du automatisk ha lurt på kostnadseffektiviteten til den interne datainnsamlingsprosessen.
Vi vet at du fortsatt er nølende til betalte kilder, og det er derfor denne delen vil fjerne skepsisen din til det og kaste lys over de skjulte kostnadene forbundet med intern datagenerering.
Er intern datainnsamling dyrt?
Ja, det er det!
Nå, her er et forseggjort svar. Utgifter er alt du bruker. Mens vi diskuterte gratis ressurser, avslørte vi at du bruker penger, tid og krefter på prosessen. Dette gjelder også for intern datainnsamling.
 På grunn av det faktum at du har spesialdefinerte berøringspunkter eller datatrakter, betyr det ikke at du ville ha det maskinklare datasett til slutt. Dataene du genererer vil fortsatt for det meste være rå og ustrukturert. Du kan ha alle dataene du trenger på ett sted, men det dataene inneholder vil være overalt.
På grunn av det faktum at du har spesialdefinerte berøringspunkter eller datatrakter, betyr det ikke at du ville ha det maskinklare datasett til slutt. Dataene du genererer vil fortsatt for det meste være rå og ustrukturert. Du kan ha alle dataene du trenger på ett sted, men det dataene inneholder vil være overalt.
Til syvende og sist vil du ende opp med å bruke penger på å betale dine ansatte, dataforskere, annotatorer, kvalitetssikringseksperter og mer. Du vil også bruke på abonnementer for merknadsverktøy og
vedlikehold av CMS, CRM og andre infrastrukturutgifter.
Dessuten er datasett nødt til å ha skjevheter og nøyaktighetsproblemer, som du trenger for å sortere dem manuelt. Og hvis du har et slitasjeproblem i AI-treningsdatateamet ditt, må du bruke penger på å rekruttere nye medlemmer, orientere dem om prosessene dine, trene dem til å bruke verktøyene dine og mer.
Du vil ende opp med å bruke mer enn hva du til slutt ville tjene på lengre sikt. Det er også anmerkningsutgifter. På et gitt tidspunkt er den totale kostnaden som påløper for å arbeide med interne data:
Påløpte kostnader = Antall kommentatorer * Kostnad per kommentator + plattformkostnad
Hvis AI-treningskalenderen din er planlagt for måneder, forestill deg utgiftene du konsekvent vil pådra deg. Så, er dette den ideelle løsningen for datainnsamlingsproblemer, eller er det noe alternativ?
Hvordan velge riktig AI Data Collection Company
Å velge et AI-datainnsamlingsselskap er ikke så komplisert eller tidkrevende som å samle inn data fra gratis ressurser. Det er bare noen få enkle faktorer du trenger å vurdere og deretter håndhilse for et samarbeid.
Når du begynner å lete etter en dataleverandør, antar vi at du har fulgt og vurdert det vi har diskutert så langt. Men her er en rask oppsummering:
- Du har en veldefinert brukssak i tankene
- Ditt markedssegment og datakrav er tydelig etablert
- Budsjettet ditt er på punkt
- Og du har en ide om mengden data du trenger
Med disse elementene merket av, la oss forstå hvordan du kan se etter en ideell leverandør av treningsdatatjenester.