Prosessen med å samle AI-treningsdata er både uunngåelig og utfordrende. Det er ingen måte vi kan hoppe over denne delen og komme direkte til det punktet at modellen vår begynner å gi meningsfulle resultater (eller resultater i utgangspunktet). Det er systematisk og sammenhengende.
Etter hvert som formålene og brukssakene til moderne AI-løsninger (kunstig intelligens) blir mer nisje, er det en økt etterspørsel etter raffinerte AI treningsdata. Med selskaper og oppstartsbedrifter som begir seg ut i nyere territorier og markedssegmenter, begynner de å operere i rom som tidligere var uutforsket. Dette gjør AI-datainnsamling desto mer intrikat og kjedelig.
Mens veien videre definitivt er skremmende, kan den forenkles med en strategisk tilnærming. Med en godt kartlagt plan kan du strømlinjeforme din AI-datainnsamling prosess og gjør det enkelt for alle involverte. Alt du trenger å gjøre er å få klarhet i dine krav og svare på noen spørsmål.
Hva er de? La oss finne det ut.
The Quintessential AI Training Data Collection Guideline
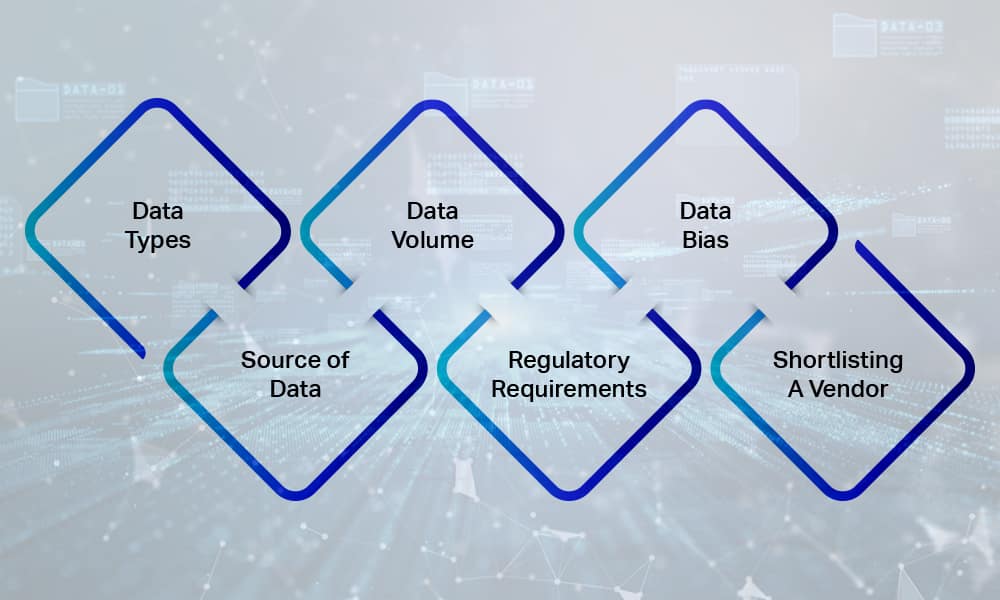
Hvilke data trenger du?
Dette er det første spørsmålet du må svare på for å kompilere meningsfulle datasett og bygge en givende AI-modell. Hvilken type data du trenger avhenger av det virkelige problemet du har tenkt å løse.
 Utvikler du en virtuell assistent? Datatypen du trenger, koker ned til taledata som har et mangfoldig utvalg av aksenter, følelser, aldre, språk, modulasjoner, uttaler og mer av publikummet ditt.
Utvikler du en virtuell assistent? Datatypen du trenger, koker ned til taledata som har et mangfoldig utvalg av aksenter, følelser, aldre, språk, modulasjoner, uttaler og mer av publikummet ditt.
Hvis du utvikler en chatbot for en fintech-løsning, trenger du tekstbasert data med en god blanding av kontekster, semantikk, sarkasme, grammatisk syntaks, tegnsetting og mer.
Noen ganger kan du også trenge en blanding av flere typer data basert på problemet du løser og hvordan du løser det. For eksempel vil en AI-modell for et IoT-system som sporer utstyrets helse kreve bilder og opptak fra datasyn for å oppdage funksjonsfeil og bruke historiske data som tekst, statistikk og tidslinjer for å behandle dem sammen og nøyaktig forutsi resultater.
-
Hva er datakilden din?
ML datakilde er vanskelig og komplisert. Dette påvirker direkte resultatene modellene dine vil levere i fremtiden, og det må utvises forsiktighet på dette tidspunktet for å etablere veldefinerte datakilder og kontaktpunkter.
For å komme i gang med datainnhenting kan du se etter interne datagenereringskontaktpunkter. Disse datakildene er definert av virksomheten din og for virksomheten din. Det betyr at de er relevante for brukssaken din.
Hvis du ikke har en intern ressurs eller hvis du trenger flere datakilder, kan du sjekke ut gratisressurser som arkiver, offentlige datasett, søkemotorer og mer. Bortsett fra disse kildene, har du også dataleverandører, som kan hente de nødvendige dataene dine og levere dem til deg fullstendig kommentert.
Når du bestemmer deg for datakilden din, bør du vurdere det faktum at du vil trenge volumer etter volumer av data i det lange løp, og de fleste datasettene er ustrukturerte, de er rå og over alt.
For å unngå slike problemer henter de fleste bedrifter vanligvis datasettene sine fra leverandører, som leverer maskinklare filer som er nøyaktig merket av bransjespesifikke SMB-er.
-
Hvor mye? – Volum av data trenger du?
La oss utvide den siste pekeren litt mer. AI-modellen din vil bli optimalisert for nøyaktige resultater bare når den er konsekvent trent med mer volum av kontekstuelle datasett. Dette betyr at du kommer til å kreve et enormt datavolum. Når det gjelder AI-treningsdata, er det ikke noe som heter for mye data.
Så det er ingen tak som sådan, men hvis du virkelig må bestemme deg for mengden data du trenger, kan du bruke budsjettet som en avgjørende faktor. AI-treningsbudsjett er et helt annet ballspill, og vi har grundig dekket det tema her. Du kan sjekke det ut og få en ide om hvordan du kan nærme deg og balansere datavolum og utgifter.
-
Regulatoriske krav til datainnsamling
 Etikk og sunn fornuft tilsier det faktum at datainnhenting bør komme fra rene kilder. Dette er mer kritisk når du utvikler en AI-modell med helsedata, fintech-data og andre sensitive data. Når du henter datasettene dine, implementerer du regulatoriske protokoller og samsvar som f.eks GDPR, HIPAA-standarder og andre relevante standarder for å sikre at dataene dine er rene og fri for lovligheter.
Etikk og sunn fornuft tilsier det faktum at datainnhenting bør komme fra rene kilder. Dette er mer kritisk når du utvikler en AI-modell med helsedata, fintech-data og andre sensitive data. Når du henter datasettene dine, implementerer du regulatoriske protokoller og samsvar som f.eks GDPR, HIPAA-standarder og andre relevante standarder for å sikre at dataene dine er rene og fri for lovligheter.Hvis du henter dataene dine fra leverandører, se etter lignende samsvar også. Ikke på noe tidspunkt bør en kundes eller brukers sensitive informasjon kompromitteres. Dataene bør avidentifiseres før de mates inn i maskinlæringsmodeller.
-
Håndtering av databias
Databias kan sakte drepe AI-modellen din. Betrakt det som en langsom gift som bare blir oppdaget med tiden. Bias sniker seg inn fra ufrivillige og mystiske kilder og kan lett hoppe over radaren. Når din AI treningsdata er partisk, er resultatene skjeve og ofte ensidige.
For å unngå slike tilfeller, sørg for at dataene du samler inn er så forskjellige som mulig. Hvis du for eksempel samler inn taledatasett, inkluderer datasett fra flere etnisiteter, kjønn, aldersgrupper, kulturer, aksenter og mer for å imøtekomme de ulike typene mennesker som ville ende opp med å bruke tjenestene dine. Jo rikere og mer varierte dataene dine er, desto mindre partiske vil de sannsynligvis være.
-
Velge riktig datainnsamlingsleverandør
Når du velger å outsource datainnsamlingen din, må du først bestemme hvem du skal outsource. Den rette leverandøren av datainnsamling har en solid portefølje, en transparent samarbeidsprosess og tilbyr skalerbare tjenester. Den perfekte passformen er også den som etisk henter AI-treningsdata og sikrer at hver enkelt overholdelse blir overholdt. En prosess som er tidkrevende kan ende opp med å forlenge AI-utviklingsprosessen din hvis du velger å samarbeide med feil leverandør.
Så se på deres tidligere arbeider, sjekk om de har jobbet med bransjen eller markedssegmentet du skal begi deg inn i, vurder engasjementet deres og få betalte prøver for å finne ut om leverandøren er en ideell partner for dine AI-ambisjoner. Gjenta prosessen til du finner den rette.
Innpakning Up
AI-datainnsamling koker ned til disse spørsmålene, og når du har sortert disse tipsene, kan du være sikker på at AI-modellen din vil forme seg slik du ønsket. Bare ikke ta forhastede beslutninger. Det tar år å utvikle den ideelle AI-modellen, men bare minutter å få kritikk på den. Unngå disse ved å bruke våre retningslinjer.
Lykke til!