I løpet av det siste tiåret eller mindre var hver bilprodusent du møtte begeistret over utsiktene til selvkjørende biler som oversvømmet markedet. Mens noen få store bilprodusenter har lansert 'ikke-helt-autonome' kjøretøyer som kan kjøre seg selv nedover motorveien (med konstant vakt fra sjåførene, selvfølgelig), har den autonome teknologien ikke skjedd slik eksperter trodde.
I 2019, globalt, var det ca 31 millioner autonome kjøretøy (en viss grad av autonomi) i operasjoner. Dette tallet er anslått å vokse til 54 millioner innen år 2024. Trendene viser at markedet kan vokse med 60 % til tross for en nedgang på 3 % i 2020.
Selv om det er mange grunner til at selvkjørende biler kan lanseres mye senere enn forventet, er en hovedårsak mangelen på kvalitetsopplæringsdata når det gjelder volum, mangfold og validering. Men hvorfor er treningsdata viktig for utvikling av autonome kjøretøy?
Viktigheten av treningsdata for autonome kjøretøy
Autonome kjøretøy er mer datadrevne og dataavhengige enn noen annen applikasjon av AI. Kvaliteten på autonome kjøretøysystemer avhenger i stor grad av typen, volumet og mangfoldet av treningsdata som brukes.
For å sikre at autonome kjøretøy kan kjøre med begrenset eller ingen menneskelig interaksjon, må de forstå, gjenkjenne og samhandle med sanntidsstimuli som finnes på gatene. For at dette skal skje, flere nevrale nettverk må samhandle og behandle de innsamlede dataene fra sensorer for å levere sikker navigasjon.
Hvordan skaffe opplæringsdata for autonome kjøretøy?
Et pålitelig AV-system er trent på alle mulige scenarioer et kjøretøy kan møte i sanntid. Den må være forberedt på å gjenkjenne objekter og ta hensyn til miljøvariabler for å produsere nøyaktig kjøretøyadferd. Men det er en utfordring å samle så store mengder datasett for å takle hver kantsak nøyaktig.
For å trene AV-systemet på riktig måte, brukes video- og bildekommentarteknikker for å identifisere og beskrive objekter i et bilde. Treningsdata samles inn ved hjelp av kameragenererte bilder, og identifiserer bildene ved å kategorisere og merke dem nøyaktig.
Kommenterte bilder hjelper maskinlæringssystemer og datamaskiner med å lære å utføre nødvendige oppgaver. Kontekstuelle ting som signaler, veiskilt, fotgjengere, værforhold, avstanden mellom kjøretøy, dybde og annen relevant informasjon er gitt.
Flere førsteklasses selskaper tilbyr opplæringsdatasett i ulike bilde- og videoannotering formater som utviklere kan bruke til å utvikle AI-modeller.
Hvor kommer treningsdataene fra?
Autonome kjøretøy bruker en rekke sensorer og enheter for å samle, gjenkjenne og tolke informasjonen rundt miljøet. Ulike data og merknader kreves for å utvikle høyytende AV-systemer drevet av kunstig intelligens.
Noen av verktøyene som brukes er:
Kamera:
Kameraene på kjøretøyet tar opp 3D- og 2D-bilder og videoer
Radar:
Radar gir viktige data til kjøretøyet angående objektsporing, deteksjon og bevegelsesforutsigelse. Det bidrar også til å bygge en datarik representasjon av det dynamiske miljøet.

LiDaR (lysdeteksjon og rekkevidde):
For å tolke 2D-bilder nøyaktig i et 3D-rom, er det viktig å bruke LiDAR. LiDAR hjelper med å måle dybde og avstand og nærhetsføling ved hjelp av laser.
Pek på merk mens du samler inn opplæringsdata for autonome kjøretøy
Trening av et selvkjørende kjøretøy er ikke en engangsoppgave. Det krever kontinuerlig forbedring. Et helt autonomt kjøretøy kan være et tryggere alternativ til førerløse biler som trenger menneskelig assistanse. Men for dette må systemet trenes på store mengder forskjellige og treningsdata av høy kvalitet.
Volum og mangfold
Et bedre og mer pålitelig system kan utvikles når du trener din maskinlæring modell på store mengder forskjellige datasett. En datastrategi på plass som nøyaktig kan identifisere når et datasett er tilstrekkelig og når det er nødvendig med erfaring fra den virkelige verden.
Visse aspekter ved kjøring kommer bare fra virkelige opplevelser. For eksempel bør et autonomt kjøretøy forutse avvikende scenarier i den virkelige verden, som å svinge uten å signalisere eller møte en fotgjenger som går på tur.
Mens høy kvalitet datanotering hjelper i stor grad, anbefales det også å innhente data når det gjelder volum og mangfold i løpet av opplæring og erfaring.
Høy nøyaktighet i merknader
Maskinlærings- og dyplæringsmodellene dine må trenes på rene og nøyaktige data. Autonom kjører biler blir mer pålitelige og registrerer høye nivåer av nøyaktighet, men de må fortsatt gå fra 95 % nøyaktighet til 99 %. For å gjøre det, må de oppfatte veien bedre og forstå de uvanlige reglene for menneskelig oppførsel.
Bruk av kvalitetsdatamerkingsteknikker kan bidra til å forbedre nøyaktigheten til maskinlæringsmodellen.
- Begynn med å identifisere hull og forskjeller i informasjonsflyten og hold kravene til datamerking oppdatert.
- Utvikle strategier for å adressere virkelige fordelsscenarier.
- Forbedre regelmessig modellen og kvalitetsstandardene for å gjenspeile de siste treningsmålene.
- Alltid samarbeid med en pålitelig og erfaren dataopplæringspartner som bruker den nyeste merkingen og annoteringsteknikker og beste praksis.
Mulige brukstilfeller
Objektdeteksjon og sporing
Flere merknadsteknikker brukes til å kommentere objekter som fotgjengere, biler, veisignaler og mer i et bilde. Det hjelper autonome kjøretøy med å oppdage og spore ting med større nøyaktighet.
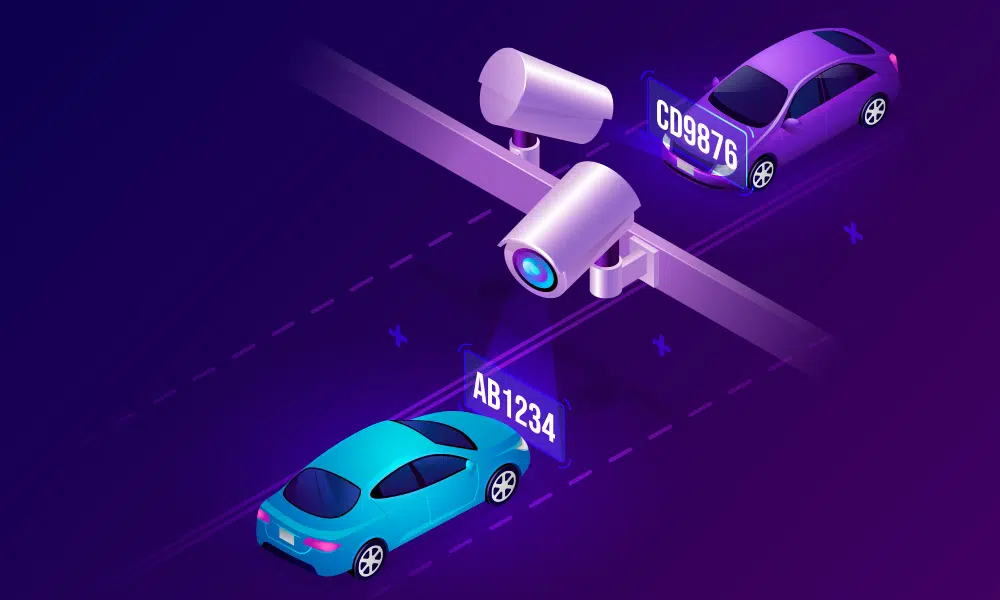
Registrering av nummerskilt
 Ved hjelp av markeringsboksbildemerkingsteknikken kan nummerskilt enkelt lokaliseres og trekkes ut fra bilder av kjøretøy.
Ved hjelp av markeringsboksbildemerkingsteknikken kan nummerskilt enkelt lokaliseres og trekkes ut fra bilder av kjøretøy.Analyserer semafor
Igjen, ved å bruke avgrensningsboksteknikken, kan signaler og skilt lett identifiseres og kommenteres.
Fotgjengersporingssystem
Fotgjengersporing gjøres ved å spore og kommentere fotgjengerens bevegelse i hver videoramme, slik at det autonome kjøretøyet nøyaktig kan finne fotgjengernes bevegelser.
Kjørefeltdifferensiering
Fildifferensiering spiller en avgjørende rolle i utviklingen av autonome kjøretøysystem. I autonome kjøretøy tegnes linjer over baner, gater og fortau ved hjelp av polyline-annotering for å muliggjøre nøyaktig kjørefeltdifferensiering.
ADAS-systemer
Avanserte førerassistentsystemer hjelper autonome kjøretøy med å oppdage veiskilt, fotgjengere, andre biler, parkeringshjelp og kollisjonsvarsling. For å aktivere datasyn in ADAS, må alle veiskiltbilder merkes effektivt for å gjenkjenne objekter og scenarier og iverksette tiltak i tide.
Førerovervåkingssystem / Overvåking i kabinen
Overvåking i kabinen bidrar også til å sikre sikkerheten til passasjerene i kjøretøyet og andre. Et kamera plassert inne i kabinen samler viktig sjåførinformasjon som døsighet, øyeblikk, distraksjon, følelser og mer. Disse bildene i kabinen er nøyaktig kommentert og brukt til opplæring av maskinlæringsmodeller.
 Ved hjelp av markeringsboksbildemerkingsteknikken kan nummerskilt enkelt lokaliseres og trekkes ut fra bilder av kjøretøy.
Ved hjelp av markeringsboksbildemerkingsteknikken kan nummerskilt enkelt lokaliseres og trekkes ut fra bilder av kjøretøy.Shaip er et ledende selskap for datakommentarer, som spiller en avgjørende rolle i å gi bedrifter opplæringsdata av høy kvalitet for å drive autonome kjøretøysystemer. Våre bildemerking og annoteringsnøyaktighet har hjulpet med å bygge ledende AI-produkter i ulike industrisegmenter, som helsevesen, detaljhandel og bilindustrien.
Vi tilbyr store mengder varierte opplæringsdatasett for alle dine maskinlærings- og dyplæringsmodeller til konkurransedyktige priser.
Gjør deg klar til å transformere AI-prosjektene dine med en pålitelig og erfaren leverandør av opplæringsdata.