
Hva er tekstkommentarer i maskinlæring?
Tekstkommentarer i maskinlæring refererer til å legge til metadata eller etiketter til rå tekstdata for å lage strukturerte datasett for opplæring, evaluering og forbedring av maskinlæringsmodeller. Det er et avgjørende trinn i NLP-oppgaver (natural language processing), siden det hjelper algoritmer å forstå, tolke og lage spådommer basert på tekstinndata.
Tekstkommentarer er viktige fordi det bidrar til å bygge bro mellom ustrukturerte tekstdata og strukturerte, maskinlesbare data. Dette gjør det mulig for maskinlæringsmodeller å lære og generalisere mønstre fra de kommenterte eksemplene.
Merknader av høy kvalitet er avgjørende for å bygge nøyaktige og robuste modeller. Dette er grunnen til at nøye oppmerksomhet på detaljer, konsistens og domeneekspertise er avgjørende i tekstkommentarer.
Typer tekstkommentarer

Når du trener NLP-algoritmer, er det viktig å ha store annoterte tekstdatasett skreddersydd for hvert prosjekts unike behov. Så, for utviklere som ønsker å lage slike datasett, her er en enkel oversikt over fem populære typer tekstkommentarer.

Sentimentkommentar
Sentimentkommentar identifiserer en teksts underliggende følelser, meninger eller holdninger. Annotatører merker tekstsegmenter med positive, negative eller nøytrale følelser. Sentimentanalyse, en nøkkelapplikasjon av denne merknadstypen, er mye brukt i overvåking av sosiale medier, analyse av tilbakemeldinger fra kunder og markedsundersøkelser.
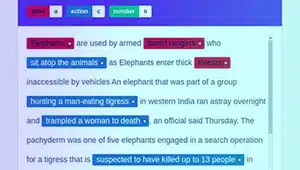
Hensiktskommentar
Hensiktsanmerkning har som mål å fange hensikten eller målet bak en gitt tekst. I denne typen merknader tildeler annotatorer etiketter til tekstsegmenter som representerer spesifikke brukerintensjoner, for eksempel å be om informasjon, be om noe eller uttrykke en preferanse.
Semantisk kommentar
Semantisk merknad identifiserer betydningen og relasjonene mellom ord, setninger og setninger. Annotatorer bruker ulike teknikker, for eksempel tekstsegmentering, dokumentanalyse og tekstutvinning, for å merke og klassifisere de semantiske egenskapene til tekstelementer.

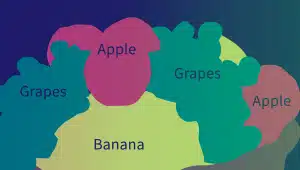
Enhetsmerknad
Entitetsannotering er avgjørende for å lage chatbot-treningsdatasett og andre NLP-data. Det innebærer å finne og merke enheter i tekst. Typer enhetsannotering inkluderer:

Språklig merknad
Språklig merknad omhandler de strukturelle og grammatiske aspektene ved språk. Den omfatter forskjellige underoppgaver, for eksempel del-av-tale-tagging, syntaktisk analyse og morfologisk analyse.

Forsikring
Tekstkommentarer hjelper forsikringsselskaper med å analysere tilbakemeldinger fra kunder, behandle krav og oppdage svindel. Ved å bruke AI-modeller som er trent på kommenterte datasett, kan forsikringsselskapene:

Banking
Tekstkommentarer forenkler forbedret kundeservice, svindeloppdagelse og dokumentanalyse i bankvirksomhet. AI-systemer trent på annoterte data kan:

Telecom
Tekstkommentarer gjør det mulig for telekomselskaper å forbedre kundestøtten, overvåke sosiale medier og håndtere nettverksproblemer. Maskinlæringsmodeller trent på kommenterte datasett kan:
Hvordan kommentere tekstdata?
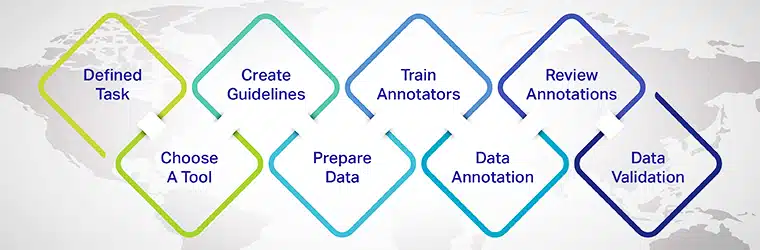
- Definer kommentaroppgaven: Bestem den spesifikke NLP-oppgaven du vil ta opp, for eksempel sentimentanalyse, navngitt enhetsgjenkjenning eller tekstklassifisering.
- Velg et passende annoteringsverktøy: Velg et tekstkommentarverktøy eller -plattform som oppfyller prosjektkravene dine og støtter de ønskede merknadstypene.
- Lag retningslinjer for kommentarer: Utvikle klare og konsistente retningslinjer som kommentatorer kan følge, og sikre høykvalitets og nøyaktige kommentarer.
- Velg og klargjør dataene: Samle et mangfoldig og representativt utvalg av rå tekstdata som kommentatorene kan jobbe med.
- Trene og evaluer annotatorer: Gi opplæring og kontinuerlig tilbakemelding til kommentatorer, for å sikre konsistens og kvalitet i merknadsprosessen.
- Annoter dataene: Annotatorer merker teksten i henhold til de definerte retningslinjene og merknadstypene.
- Se gjennom og avgrens merknader: Gjennomgå og avgrens merknadene regelmessig, adresser eventuelle inkonsekvenser eller feil og forbedre datasettet iterativt.
- Del datasettet: Del opp de kommenterte dataene i trenings-, validerings- og testsett for å trene og evaluere maskinlæringsmodellen.
Hva kan Shaip gjøre for deg?
Shaip tilbyr skreddersydde løsninger for tekstkommentarer for å drive AI- og maskinlæringsapplikasjonene dine i ulike bransjer. Med et sterkt fokus på høykvalitets og nøyaktige merknader, kan Shaips erfarne team og avanserte merknadsplattform håndtere ulike tekstdata.
Enten det er sentimentanalyse, navngitt enhetsgjenkjenning eller tekstklassifisering, leverer Shaip tilpassede datasett for å bidra til å forbedre AI-modellenes språkforståelse og ytelse.
Stol på Shaip for å strømlinjeforme tekstkommentarprosessen og sikre at AI-systemene dine når sitt fulle potensial.

