Data er supermakten som forvandler det digitale landskapet i dagens verden. Fra e-poster til innlegg på sosiale medier, det er data overalt. Det er sant at bedrifter aldri har hatt tilgang til så mye data, men er det nok å ha tilgang til data? Den rike informasjonskilden blir ubrukelig eller foreldet når den ikke blir behandlet.
Ustrukturert tekst kan være en rik kilde til informasjon, men den vil ikke være nyttig for bedrifter med mindre dataene er organisert, kategorisert og analysert. Ustrukturerte data, som tekst, lyd, videoer og sosiale medier, utgjør 80 -90% av alle data. Videre er det rapportert at knapt 18 % av organisasjonene utnytter organisasjonens ustrukturerte data.
Manuell siling gjennom terabyte med data som er lagret på serverne er en tidkrevende og ærlig talt umulig oppgave. Men med fremskritt innen maskinlæring, naturlig språkbehandling og automatisering, er det mulig å strukturere og analysere tekstdata raskt og effektivt. Det første trinnet i dataanalyse er tekst klassifisering.
Hva er tekstklassifisering?
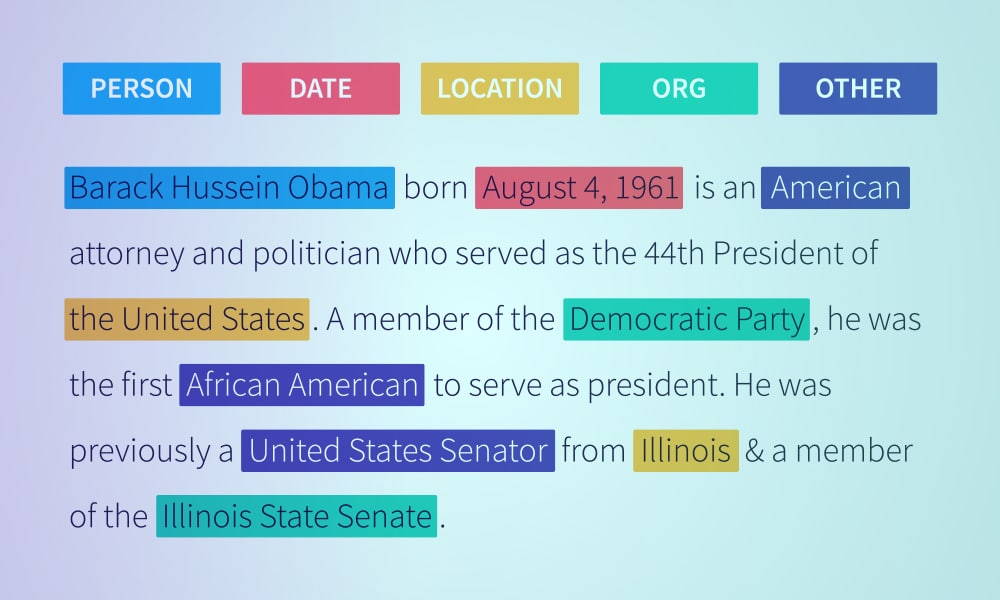
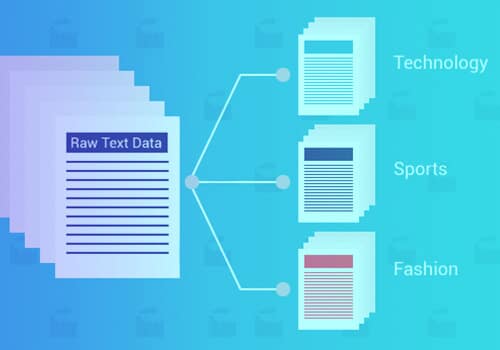
Tekstklassifisering eller kategorisering er prosessen med å gruppere tekst i forhåndsbestemte kategorier eller klasser. Ved å bruke denne tilnærmingen til maskinlæring, kan alle tekst – dokumenter, nettfiler, studier, juridiske dokumenter, medisinske rapporter og mer – kan klassifiseres, organiseres og struktureres.
Tekstklassifisering er det grunnleggende trinnet i naturlig språkbehandling som har flere bruksområder i spam-deteksjon. Sentimentanalyse, intensjonsdeteksjon, datamerking og mer.
Tilfeller av mulig bruk av tekstklassifisering
 Det er flere fordeler med å bruke maskinlæringstekstklassifisering, for eksempel skalerbarhet, analysehastighet, konsistens og muligheten til å ta raske beslutninger basert på sanntidssamtaler.
Det er flere fordeler med å bruke maskinlæringstekstklassifisering, for eksempel skalerbarhet, analysehastighet, konsistens og muligheten til å ta raske beslutninger basert på sanntidssamtaler.
Når ML-modellen er trent på AI som automatisk kategoriserer varer under forhåndsinnstilte kategorier, kan du raskt konvertere tilfeldige nettlesere til kunder.
Tekstklassifiseringsprosess
Tekstklassifiseringsprosessen starter med forhåndsbehandling, funksjonsvalg, utvinning og klassifisering av data.

Forbehandling
Tokenisering: Tekst brytes ned i mindre og enklere tekstformer for enkel klassifisering.
normalisering: All tekst i et dokument må være på samme forståelsesnivå. Noen former for normalisering inkluderer,
- Opprettholde grammatiske eller strukturelle standarder på tvers av teksten, for eksempel fjerning av mellomrom eller tegnsetting. Eller opprettholde små bokstaver gjennom hele teksten.
- Fjerne prefikser og suffikser fra ord og bringe dem tilbake til rotordet.
- Å fjerne stoppord som 'og' 'er' 'den' og flere som ikke tilfører teksten verdi.
Funksjonsvalg
Funksjonsvalg er et grunnleggende trinn i tekstklassifisering. Prosessen er rettet mot å representere tekster med det mest relevante trekket. Funksjonsvalg hjelper til med å fjerne irrelevante data og forbedre nøyaktigheten.
Funksjonsvalg reduserer inngangsvariabelen i modellen ved å bruke bare de mest relevante dataene og eliminere støy. Basert på typen løsning du søker, kan AI-modellene dine designes for å velge bare de relevante funksjonene fra teksten.
Funksjonsekstraksjon
Funksjonsutvinning er et valgfritt trinn som enkelte virksomheter tar for å trekke ut flere nøkkelfunksjoner i dataene. Funksjonsutvinning bruker flere teknikker, for eksempel kartlegging, filtrering og gruppering. Den primære fordelen med å bruke funksjonsekstraksjon er – det hjelper til med å fjerne overflødige data og forbedre hastigheten som ML-modellen utvikles med.
Merking av data til forhåndsbestemte kategorier
Merking av tekst til forhåndsdefinerte kategorier er det siste trinnet i tekstklassifisering. Det kan gjøres på tre forskjellige måter,
- Manuell merking
- Regelbasert matching
- Læringsalgoritmer - Læringsalgoritmene kan videre klassifiseres i to kategorier som overvåket tagging og uovervåket tagging.
- Overvåket læring: ML-modellen kan automatisk justere taggene med eksisterende kategoriserte data i overvåket tagging. Når kategoriserte data allerede er tilgjengelige, kan ML-algoritmene kartlegge funksjonen mellom taggene og teksten.
- Uovervåket læring: Det skjer når det er mangel på tidligere eksisterende taggede data. ML-modeller bruker klynging og regelbaserte algoritmer for å gruppere lignende tekster, for eksempel basert på produktkjøpshistorikk, anmeldelser, personlige detaljer og billetter. Disse brede gruppene kan analyseres videre for å trekke verdifull kundespesifikk innsikt som kan brukes til å designe skreddersydde kundetilnærminger.
Det er flere brukstilfeller for tekstklassifisering på tvers av bransjer. Selv om innsamling, gruppering, klassifisering og utvinning av verdifull innsikt fra tekstdata alltid har blitt brukt på flere felt, finner tekstklassifisering sitt potensiale innen markedsføring, produktutvikling, kundeservice, ledelse og administrasjon. Det hjelper bedrifter med å få konkurransedyktig intelligens, markeds- og kundekunnskap og ta datastøttede forretningsbeslutninger.
Det er ikke lett å utvikle et effektivt og innsiktsfullt tekstklassifiseringsverktøy. Likevel, med Shaip som datapartner, kan du utvikle et effektivt, skalerbart og kostnadseffektivt AI-basert tekstklassifiseringsverktøy. Vi har tonnevis av nøyaktig kommenterte og klare til bruk datasett som kan tilpasses for modellens unike krav. Vi gjør teksten din til et konkurransefortrinn; ta kontakt i dag.