
Kunstig intelligens fremmer menneskelignende interaksjoner med datasystemer, mens Machine Learning lar disse maskinene lære å etterligne menneskelig intelligens gjennom hver interaksjon. Men hva driver disse svært avanserte ML- og AI-verktøyene? Dataanmerkning.
Data er råmaterialet som driver ML-algoritmer – jo mer data du bruker, jo bedre blir AI-produktet. Selv om det er kritisk viktig å ha tilgang til store mengder data, er det like viktig å sikre at de er nøyaktig kommentert for å gi gjennomførbare resultater. Dataannotering er datakraftverket bak avansert, pålitelig og nøyaktig ML-algoritmisk ytelse.
Rollen til dataannotering i AI-trening
Dataannotering spiller en nøkkelrolle i ML-trening og den generelle suksessen til AI-prosjekter. Den hjelper til med å identifisere spesifikke bilder, data, mål og videoer og merker dem for å gjøre det lettere for maskinen å identifisere mønstre og klassifisere data. Det er en menneskelig ledet oppgave som trener ML-modellen til å lage nøyaktige spådommer.
Hvis datakommentaren ikke utføres nøyaktig, kan ikke ML-algoritmen enkelt knytte attributter til objekter.
Viktigheten av kommenterte treningsdata for AI-systemer
Dataannotering muliggjør nøyaktig funksjon av ML-modeller. Det er en udiskutabel sammenheng mellom nøyaktigheten og presisjonen til datakommentarer og suksessen til AI-prosjektet.
Den globale AI-markedsverdien, anslått til å være 119 milliarder dollar i 2022, er spådd å nå $ 1,597 milliarder 2030, vokste med en CAGR på 38 % i løpet av perioden. Mens hele AI-prosjektet går gjennom flere kritiske trinn, er datakommentarstadiet der prosjektet ditt er på det viktigste stadiet.
Å samle inn data for datas skyld kommer ikke til å hjelpe prosjektet ditt mye. Du trenger enorme mengder relevant data av høy kvalitet for å implementere AI-prosjektet ditt på en vellykket måte. Omtrent 80 % av tiden din i ML-prosjektutvikling brukes på datarelaterte oppgaver, som merking, skrubbing, aggregering, identifisering, utvidelse og merking.
Dataannotering er et område hvor mennesker har en fordel fremfor datamaskiner fordi vi har den medfødte evnen til å tyde hensikter, vasse gjennom tvetydighet og klassifisere usikker informasjon.
Hvorfor er datamerking viktig?
Verdien og troverdigheten til din kunstige intelligens-løsning avhenger i stor grad av kvaliteten på datainndata som brukes til modelltrening.
En maskin kan ikke behandle bilder slik vi gjør; de må trenes til å gjenkjenne mønstre gjennom trening. Siden maskinlæringsmodeller imøtekommer et bredt spekter av applikasjoner – kritiske løsninger som helsevesen og autonome kjøretøy – der enhver feil i datakommentarer kan ha farlige konsekvenser.
Datakommentarer sikrer at AI-løsningen din fungerer fullt ut. Trening av en ML-modell til å tolke miljøet nøyaktig gjennom mønstre og korrelasjoner, lage spådommer og iverksette nødvendige handlinger krever svært kategorisert og kommentert treningsdata. Merknaden viser ML-modellen den nødvendige prediksjonen ved å merke, transkribere og merke kritiske funksjoner i datasettet.
Veiledet læring
Før vi graver dypere inn i datakommentarer, la oss nøste opp datakommentarer gjennom overvåket og uovervåket læring.
En underkategori av maskinlæringsovervåket maskinlæring indikerer AI-modellopplæring ved hjelp av et godt merket datasett. I en overvåket læringsmetode er noen data allerede nøyaktig merket og kommentert. ML-modellen, når den eksponeres for nye data, bruker treningsdataene for å komme med en nøyaktig prediksjon basert på de merkede dataene.
For eksempel er ML-modellen trent på et skap fullt av forskjellige typer klær. Det første trinnet i treningen vil være å trene modellen med forskjellige typer klær ved å bruke egenskapene og egenskapene til hvert tøystykke. Etter opplæringen vil maskinen kunne identifisere separate klesplagg ved å bruke sin tidligere kunnskap eller opplæring. Veiledet læring kan kategoriseres i klassifisering (basert på kategori) og regresjon (basert på reell verdi).
Hvordan datakommentarer påvirker ytelsen til AI-systemer
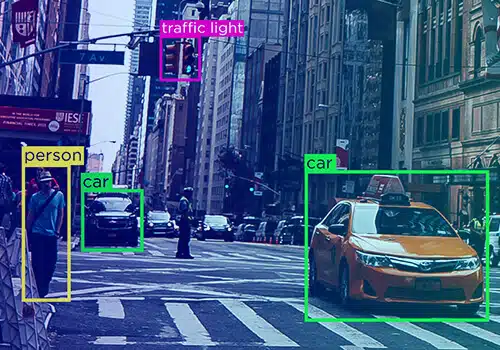 Data er aldri en enkelt enhet – de antar forskjellige former – tekst, video og bilde. Unødvendig å si kommer datakommentarer i forskjellige former.
Data er aldri en enkelt enhet – de antar forskjellige former – tekst, video og bilde. Unødvendig å si kommer datakommentarer i forskjellige former.
For at maskinen skal forstå og nøyaktig identifisere ulike enheter, er det viktig å understreke kvaliteten på navngitt enhetsmerking. En feil i merking og merknad, og ML kunne ikke skille mellom Amazon – e-handelsbutikken, elven eller en papegøye.
Dessuten hjelper datakommentarer maskiner med å gjenkjenne subtile hensikter – en kvalitet som kommer naturlig for mennesker. Vi kommuniserer forskjellig, og mennesker forstår både eksplisitt uttrykte tanker og underforståtte budskap. For eksempel kan svar eller anmeldelser på sosiale medier være både positive og negative, og ML bør kunne forstå begge deler. 'Flott sted. Vil besøke igjen.' Det er en positiv setning mens 'For et flott sted det pleide å være! Vi pleide å elske dette stedet!' er negativ, og menneskelig merknad kan gjøre denne prosessen mye enklere.

Utfordringer i datakommentarer og hvordan man kan overvinne dem
To hovedutfordringer i dataannotering er kostnad og nøyaktighet.
Behovet for svært nøyaktige data: Skjebnen til AI- og ML-prosjekter avhenger av kvaliteten på annoterte data. ML- og AI-modellene må konsekvent mates med godt klassifiserte data som kan trene modellen til å gjenkjenne korrelasjonen mellom variabler.
Behovet for store datamengder: Alle ML- og AI-modeller trives med store datasett – et enkelt ML-prosjekt trenger minst tusenvis av merkede elementer.
Behovet for ressurser: AI-prosjekter er ressursavhengige, både når det gjelder kostnader, tid og arbeidsstyrke. Uten noen av disse, kan kvaliteten på datakommentarprosjektet ditt gå galt.
[Les også: Videokommentar for maskinlæring ]
Beste praksis for datakommentarer
Verdien av datakommentarer er tydelig i dens innvirkning på resultatet av AI-prosjektet. Hvis datasettet du trener ML-modellene dine på er fulle av inkonsekvenser, partisk, ubalansert eller ødelagt, kan AI-løsningen din være en feil. I tillegg, hvis etikettene er feil og merknaden er inkonsekvent, vil AI-løsningen også føre til unøyaktige spådommer. Så hva er de beste fremgangsmåtene for datakommentarer?
Tips for effektiv og effektiv datakommentar
- Sørg for at dataetikettene du lager er spesifikke og konsistente med prosjektbehovet og likevel generelle nok til å imøtekomme alle mulige variasjoner.
- Annoter store mengder data som er nødvendige for å trene maskinlæringsmodellen. Jo flere data du merker, desto bedre blir resultatet av modellopplæringen.
- Retningslinjer for datakommentarer går langt i å etablere kvalitetsstandarder og sikre konsistens gjennom hele prosjektet og på tvers av flere annotatorer.
- Siden datakommentarer kan være kostbare og arbeidskraftsavhengige, er det fornuftig å sjekke ut forhåndsmerkede datasett fra tjenesteleverandører.
- For å hjelpe til med nøyaktige datakommentarer og opplæring, ta inn effektiviteten til human-in-the-loop for å bringe mangfold og håndtere kritiske saker sammen med mulighetene til merknadsprogramvare.
- Prioriter kvalitet ved å teste annotatorene for kvalitetsoverholdelse, nøyaktighet og konsistens.
Viktigheten av kvalitetskontroll i merknadsprosessen
 Kvalitetsdatakommentarer er livsnerven i høyytende AI-løsninger. Godt kommenterte datasett hjelper AI-systemer med å yte upåklagelig godt, selv i et kaotisk miljø. På samme måte er det motsatte også like sant. Et datasett spekket med annoteringsunøyaktigheter kommer til å kaste opp inkonsekvente løsninger.
Kvalitetsdatakommentarer er livsnerven i høyytende AI-løsninger. Godt kommenterte datasett hjelper AI-systemer med å yte upåklagelig godt, selv i et kaotisk miljø. På samme måte er det motsatte også like sant. Et datasett spekket med annoteringsunøyaktigheter kommer til å kaste opp inkonsekvente løsninger.
Så kvalitetskontroll i bildet, videomerkingen og merkingsprosessen spiller en betydelig rolle i AI-resultatet. Å opprettholde kvalitetskontrollstandarder gjennom hele merknadsprosessen er imidlertid utfordrende for små og store selskaper. Avhengigheten av ulike typer annoteringsverktøy og mangfoldig annoteringsarbeidsstyrke kan være vanskelig å vurdere og opprettholde kvalitetskonsistens.
Det er vanskelig å opprettholde kvaliteten på annotatorer for distribuerte eller fjernarbeidende data, spesielt for de som ikke er kjent med de nødvendige standardene. I tillegg kan feilsøking eller feilretting ta tid ettersom det må identifiseres på tvers av en distribuert arbeidsstyrke.
Løsningen ville være å trene annotatørene, involvere en veileder, eller la flere dataannotatorer se på og gjennomgå jevnaldrende for datasettkommentarnøyaktighet. Til slutt, regelmessig testing av annotatorene på deres kunnskap om standardene.
Annotatorers rolle og hvordan velge riktige annotatorer for dataene dine
Menneskelige annotatorer har nøkkelen til et vellykket AI-prosjekt. Dataannotatorer sikrer at dataene er nøyaktig, konsekvent og pålitelig kommentert siden de kan gi kontekst, forstå intensjoner og legge grunnlaget for grunnsannheter i dataene.
Noen data blir kunstig eller automatisk kommentert ved hjelp av automatiseringsløsninger med en rimelig grad av pålitelighet. Du kan for eksempel laste ned hundretusenvis av bilder av hus fra Google og lage dem som et datasett. Nøyaktigheten til datasettet kan imidlertid bare bestemmes pålitelig etter at modellen starter ytelsen.
Automatisert automatisering kan gjøre ting enklere og raskere, men unektelig mindre nøyaktig. På baksiden kan en menneskelig annotator være tregere og dyrere, men de er mer nøyaktige.
Annotatorer for menneskelige data kan kommentere og klassifisere data basert på deres fagkompetanse, medfødte kunnskap og spesifikke opplæring. Dataannotatorer etablerer nøyaktighet, presisjon og konsistens.
[Les også: En nybegynnerveiledning for datakommentarer: tips og beste fremgangsmåter ]
konklusjonen
For å lage et AI-prosjekt med høy ytelse, trenger du annoterte treningsdata av høy kvalitet. Selv om det kan være tidkrevende og ressurskrevende å innhente godt kommenterte data konsekvent – selv for store bedrifter – ligger løsningen i å søke tjenestene til etablerte leverandører av datakommentarer som Shaip. Hos Shaip hjelper vi deg med å skalere AI-evnene dine gjennom våre spesialisttjenester for datakommentarer ved å møte markedets og kundenes etterspørsel.


