
AI, Big Data og Machine Learning fortsetter å påvirke beslutningstakere, bedrifter, vitenskap, mediehus og en rekke bransjer over hele verden. Rapporter tyder på at den globale bruksraten for kunstig intelligens for øyeblikket er på 35% i 2022 – en gigantisk økning på 4 % fra 2021. Ytterligere 42 % av selskapene utforsker angivelig de mange fordelene med AI for virksomheten deres.
Driver de mange AI-initiativene og Maskinlæring løsninger er data. AI kan bare være like god som dataene som mater algoritmen. Data av lav kvalitet kan føre til resultater av lav kvalitet og unøyaktige spådommer.
Mens det har vært mye oppmerksomhet rundt ML- og AI-løsningsutvikling, mangler bevisstheten om hva som kvalifiserer som et kvalitetsdatasett. I denne artikkelen navigerer vi tidslinjen til AI-treningsdata av høy kvalitet og identifisere fremtiden til AI gjennom en forståelse av datainnsamling og opplæring.
Definisjon av AI-treningsdata
Når du bygger en ML-løsning er mengden og kvaliteten på opplæringsdatasettet viktig. ML-systemet krever ikke bare store mengder dynamiske, objektive og verdifulle treningsdata, men det trenger også mye av det.
Men hva er AI-treningsdata?
AI-treningsdata er en samling av merkede data som brukes til å trene ML-algoritmen til å lage nøyaktige spådommer. ML-systemet prøver å gjenkjenne og identifisere mønstre, forstå sammenhenger mellom parametere, ta nødvendige beslutninger og evaluere basert på treningsdataene.
Ta eksempelet med selvkjørende biler, for eksempel. Opplæringsdatasettet for en selvkjørende ML-modell bør inkludere merkede bilder og videoer av biler, fotgjengere, gateskilt og andre kjøretøy.
Kort sagt, for å forbedre kvaliteten på ML-algoritmen trenger du store mengder godt strukturerte, kommenterte og merkede treningsdata.
Viktigheten av kvalitetsopplæringsdata og dens utvikling
Treningsdata av høy kvalitet er nøkkelinngangen i AI- og ML-apputvikling. Data samles inn fra ulike kilder og presenteres i en uorganisert form som ikke er egnet for maskinlæringsformål. Kvalitetstreningsdata – merket, kommentert og merket – er alltid i et organisert format – ideelt for ML-trening.
Kvalitetstreningsdata gjør det lettere for ML-systemet å gjenkjenne objekter og klassifisere dem i henhold til forhåndsbestemte funksjoner. Datasettet kan gi dårlige modellresultater hvis klassifiseringen ikke er nøyaktig.
De tidlige dagene med AI-treningsdata
Til tross for at AI dominerte dagens forretnings- og forskningsverden, dominerte de første dagene før ML Kunstig intelligens var ganske annerledes.
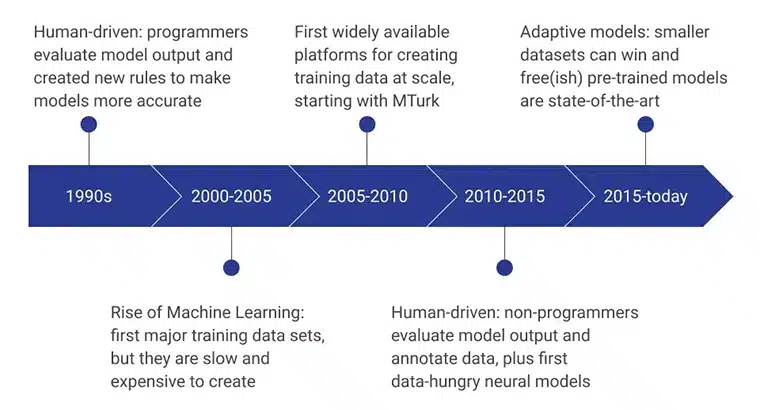
De innledende stadiene av AI-treningsdata ble drevet av menneskelige programmerere som evaluerte modellresultatet ved å konsekvent utarbeide nye regler som gjorde modellen mer effektiv. I perioden 2000 – 2005 ble det første store datasettet opprettet, og det var en ekstremt langsom, ressursavhengig og kostbar prosess. Det førte til at opplæringsdatasett ble utviklet i stor skala, og Amazons MTurk spilte en betydelig rolle i å endre folks oppfatning av datainnsamling. Samtidig tok menneskelig merking og merking også fart.
De neste årene fokuserte på ikke-programmerere å lage og evaluere datamodellene. For tiden er fokuset på forhåndstrente modeller utviklet ved bruk av avanserte metoder for innsamling av treningsdata.
Mengde over kvalitet
Da dataforskere vurderte integriteten til AI-treningsdatasett i sin tid, fokuserte dataforskere på AI-treningsdatamengde over kvalitet.
For eksempel var det en vanlig misforståelse at store databaser gir nøyaktige resultater. Selve datavolumet ble antatt å være en god indikator på verdien av data. Kvantitet er bare en av de primære faktorene som bestemmer verdien av datasettet – rollen til datakvalitet ble anerkjent.
Bevisstheten om at datakvalitet avhengig av datafullstendighet, økte pålitelighet, validitet, tilgjengelighet og aktualitet. Det viktigste er at dataegnethet for prosjektet avgjorde kvaliteten på dataene som ble samlet inn.
Begrensninger for tidlige AI-systemer på grunn av dårlige treningsdata
Dårlige treningsdata, kombinert med mangelen på avanserte datasystemer, var en av årsakene til flere uoppfylte løfter om tidlige AI-systemer.
På grunn av mangelen på kvalitetsopplæringsdata, kunne ikke ML-løsninger nøyaktig identifisere visuelle mønstre som stopper utviklingen av nevrale forskning. Selv om mange forskere identifiserte løftet om talespråkgjenkjenning, kunne ikke forskning eller utvikling av talegjenkjenningsverktøy komme til virkelighet takket være mangelen på taledatasett. En annen stor hindring for å utvikle avanserte AI-verktøy var datamaskinenes mangel på beregnings- og lagringsevner.
Skiftet til kvalitetsopplæringsdata
Det var et markant skifte i bevisstheten om at datasettets kvalitet betyr noe. For at ML-systemet nøyaktig skal etterligne menneskelig intelligens og beslutningstakingsevner, må det trives med høyvolum og høykvalitets treningsdata.
Tenk på ML-dataene dine som en undersøkelse – jo større dataeksempel størrelse, jo bedre prediksjon. Hvis prøvedataene ikke inkluderer alle variabler, kan det hende at de ikke gjenkjenner mønstre eller gir unøyaktige konklusjoner.
Fremskritt innen AI-teknologi og behovet for bedre treningsdata
 Fremskrittene innen AI-teknologi øker behovet for kvalitetsopplæringsdata.
Fremskrittene innen AI-teknologi øker behovet for kvalitetsopplæringsdata.Forståelsen av at bedre treningsdata øker sjansen for pålitelige ML-modeller ga opphav til bedre datainnsamling, merknader og merkingsmetoder. Kvaliteten og relevansen til dataene påvirket direkte kvaliteten på AI-modellen.
 Fremskrittene innen AI-teknologi øker behovet for kvalitetsopplæringsdata.
Fremskrittene innen AI-teknologi øker behovet for kvalitetsopplæringsdata.Økt fokus på datakvalitet og nøyaktighet
For at ML-modellen skal begynne å gi nøyaktige resultater, mates den på kvalitetsdatasett som går gjennom iterative dataraffineringstrinn.
For eksempel kan et menneske være i stand til å gjenkjenne en spesifikk hunderase i løpet av få dager etter å ha blitt introdusert for rasen – gjennom bilder, videoer eller personlig. Mennesker trekker fra sin erfaring og relatert informasjon for å huske og trekke frem denne kunnskapen når det er nødvendig. Likevel fungerer det ikke like lett for en maskin. Maskinen må mates med tydelig kommenterte og merkede bilder – hundrevis eller tusenvis – av den spesielle rasen og andre raser for at den skal kunne opprette forbindelsen.
En AI-modell forutsier resultatet ved å korrelere informasjonen som er trent med informasjonen presentert i virkelige verden. Algoritmen blir ubrukelig hvis treningsdataene ikke inkluderer relevant informasjon.
Viktigheten av mangfoldige og representative treningsdata
Økt datamangfold øker også kompetansen, reduserer skjevhet og øker rettferdig representasjon av alle scenarier. Hvis AI-modellen trenes ved hjelp av et homogent datasett, kan du være sikker på at den nye applikasjonen bare vil fungere for et bestemt formål og betjene en bestemt populasjon.Et datasett kan være partisk mot en bestemt populasjon, rase, kjønn, valg og intellektuelle meninger, noe som kan føre til en unøyaktig modell.
Det er viktig å sikre at hele datainnsamlingsprosessen, inkludert valg av emnegruppe, kurering, merknader og merking, er tilstrekkelig mangfoldig, balansert og representativ for befolkningen.
 Økt datamangfold øker også kompetansen, reduserer skjevhet og øker rettferdig representasjon av alle scenarier. Hvis AI-modellen trenes ved hjelp av et homogent datasett, kan du være sikker på at den nye applikasjonen bare vil fungere for et bestemt formål og betjene en bestemt populasjon.
Økt datamangfold øker også kompetansen, reduserer skjevhet og øker rettferdig representasjon av alle scenarier. Hvis AI-modellen trenes ved hjelp av et homogent datasett, kan du være sikker på at den nye applikasjonen bare vil fungere for et bestemt formål og betjene en bestemt populasjon.Fremtiden til AI-treningsdata
Den fremtidige suksessen til AI-modeller avhenger av kvaliteten og kvantiteten av treningsdataene som brukes til å trene ML-algoritmene. Det er viktig å erkjenne at dette forholdet mellom datakvalitet og kvantitet er oppgavespesifikk og ikke har noe sikkert svar.
Til syvende og sist er tilstrekkeligheten til et treningsdatasett definert av dets evne til å yte pålitelig godt for formålet det er bygget.
Fremskritt innen datainnsamling og merknadsteknikker
Siden ML er sensitiv for matet data, er det viktig å strømlinjeforme datainnsamling og merknader retningslinjer. Feil i datainnsamling, kurering, feilrepresentasjon, ufullstendige målinger, unøyaktig innhold, dataduplisering og feilmålinger bidrar til utilstrekkelig datakvalitet.
Automatisert datainnsamling gjennom datautvinning, nettskraping og datautvinning baner vei for raskere datagenerering. I tillegg fungerer ferdigpakkede datasett som en hurtigfiks datainnsamlingsteknikk.
Crowdsourcing er en annen banebrytende metode for datainnsamling. Selv om sannheten til dataene ikke kan garanteres, er det et utmerket verktøy for å samle offentlig bilde. Til slutt spesialisert datainnsamling eksperter leverer også data hentet for spesifikke formål.
Økt vekt på etiske hensyn i treningsdata
Med de raske fremskritt innen AI har flere etiske problemer dukket opp, spesielt i treningsdatainnsamling. Noen etiske hensyn ved innsamling av opplæringsdata inkluderer informert samtykke, åpenhet, partiskhet og personvern.Siden data nå inkluderer alt fra ansiktsbilder, fingeravtrykk, stemmeopptak og andre kritiske biometriske data, blir det kritisk viktig å sikre overholdelse av juridisk og etisk praksis for å unngå dyre søksmål og skade på omdømmet.
Potensialet for enda bedre kvalitet og varierte treningsdata i fremtiden
Det er et stort potensial for høykvalitets og varierte treningsdata i fremtiden. Takket være bevisstheten om datakvalitet og tilgjengeligheten til dataleverandører som imøtekommer kvalitetskravene til AI-løsninger.
Nåværende dataleverandører er dyktige til å bruke banebrytende teknologier for å etisk og lovlig skaffe enorme mengder forskjellige datasett. De har også interne team for å merke, kommentere og presentere dataene tilpasset forskjellige ML-prosjekter.
 Med de raske fremskritt innen AI har flere etiske problemer dukket opp, spesielt i treningsdatainnsamling. Noen etiske hensyn ved innsamling av opplæringsdata inkluderer informert samtykke, åpenhet, partiskhet og personvern.
Med de raske fremskritt innen AI har flere etiske problemer dukket opp, spesielt i treningsdatainnsamling. Noen etiske hensyn ved innsamling av opplæringsdata inkluderer informert samtykke, åpenhet, partiskhet og personvern.konklusjonen
Det er viktig å samarbeide med pålitelige leverandører med en akutt forståelse av data og kvalitet til utvikle avanserte AI-modeller. Shaip er det fremste annoteringsselskapet som er dyktig til å tilby tilpassede dataløsninger som oppfyller AI-prosjektets behov og mål. Samarbeid med oss og utforsk kompetansen, engasjementet og samarbeidet vi bringer til bordet.


