
Automatiske talegjenkjenningssystemer og virtuelle assistenter som Siri, Alexa og Cortana har blitt vanlige deler av livene våre. Vår avhengighet av dem øker betydelig etter hvert som de blir smartere. Fra å slå på lysene våre til å ringe til å bytte TV-kanal, bruker vi disse smarte teknologiene for å fullføre hverdagslige oppgaver.
Men har du noen gang lurt på hvordan disse talegjenkjenningssystemene fungerer?
Vel, denne bloggen vil utdanne deg om noen av grunnprinsippene for automatisk talegjenkjenning. Vi vil også utforske hvordan den fungerer og hvordan funksjonelle virtuelle assistenter som Siri er bygget.
Hva er automatisk talegjenkjenning?
Automatic Speech Recognition (ASR) er programvare som gjør det mulig for datasystemet å konvertere menneskelig tale til tekst, ved å utnytte flere kunstig intelligens og maskinlæringsalgoritmer.
Etter å ha konvertert og analysert den gitte kommandoen, svarer datamaskinen med en passende utgang for brukeren. ASR ble først introdusert i 1962, og siden den gang har den kontinuerlig forbedret driften og fått enormt rampelys på grunn av populære applikasjoner som Alexa og Siri.
Hva er prosessen for taleinnsamling for opplæring av ASR-modeller?
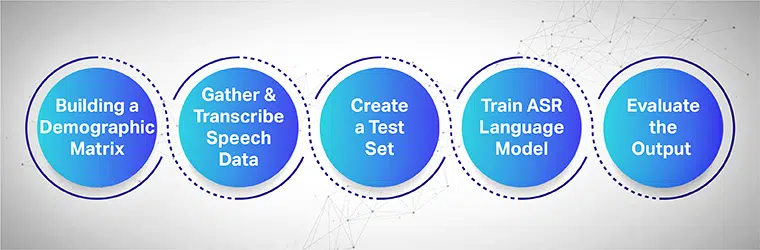
Talesamling tar sikte på å samle flere prøveopptak fra flere områder som brukes til å mate og trene ASR-modeller. ASR-systemet gir den høyeste effektiviteten når store datasett med tale og lyd samles inn og leveres til systemet.
For å fungere sømløst må de innsamlede taledatasettene inneholde all måldemografi, språk, aksenter og dialekter. Følgende prosess viser hvordan du trener maskinlæringsmodellen i flere trinn:
Start med å bygge en demografisk matrise
Samler først og fremst inn data for ulike demografier som plassering, kjønn, språk, alder og aksenter. Sørg også for å fange opp en rekke miljøstøy som gatestøy, venteromsstøy, offentlig kontorstøy, etc.
Samle og transkriber taledataene
Det neste trinnet er å samle menneskelige lyd- og taleprøver basert på forskjellige geografiske steder for å trene din ASR-modell. Det er et viktig skritt og krever at menneskelige eksperter utfører lange og korte ytringer av ord for å få den genuine følelsen av setningen og gjenta de samme setningene med forskjellige aksenter og dialekter.
Lag et separat testsett
Når du har samlet den transkriberte teksten, er neste trinn å pare den med tilsvarende lyddata. Deretter segmenterer du dataene videre og inkluderer en uttalelse fra dem. Nå, fra de segmenterte dataparene, kan du hente tilfeldige data fra et sett for videre testing.
Tren din ASR-språkmodell
Jo mer informasjon datasettene dine har, desto bedre vil den AI-trente modellen prestere. Generer derfor flere varianter av tekst og taler som du spilte inn tidligere. Omskriv de samme setningene ved å bruke forskjellige talenotasjoner.
Evaluer output og til slutt, iterer
Mål til slutt utdataene til ASR-modellen din for å fikse ytelsen. Test modellen mot et testsett for å bestemme effektiviteten. Aktiver ASR-modellen din i en tilbakemeldingssløyfe for å generere ønsket utgang og fikse eventuelle hull.
[Les også: En omfattende oversikt over automatisk talegjenkjenning]

Hva er de forskjellige brukstilfellene for talegjenkjenning?
Talegjenkjenningsteknologi er svært utbredt i mange bransjer i dag. Noen bransjer som bruker denne enorme teknologien er som følger:
 Mat industri: Matgiganter som Wendy's og McDonald's er satt til å forbedre sine kundeopplevelser ved å bruke ASR. I mange av deres utsalgssteder har de utplassert fullt funksjonelle ASR-modeller for å ta imot bestillinger, og videresende dem til matlagingsdelen for å gjøre kundebestillingen klar.
Mat industri: Matgiganter som Wendy's og McDonald's er satt til å forbedre sine kundeopplevelser ved å bruke ASR. I mange av deres utsalgssteder har de utplassert fullt funksjonelle ASR-modeller for å ta imot bestillinger, og videresende dem til matlagingsdelen for å gjøre kundebestillingen klar.- Telekommunikasjon: Vodafone er en av de største telekomleverandørene i verden. Den har designet sine kundebehandlings- og telefonrelétjenester ved å utnytte ASR-modeller som veileder deg til å løse ulike spørsmål og omdirigere samtalene dine til berørte avdelinger.
- Reise og transport: Google Android Auto eller Apple CarPlay har blitt vanlig. De fleste bruker dem til å aktivere navigasjonssystemer, sende meldinger eller bytte musikkspillelister. Men med teknologiske fremskritt blir slike systemer mer raffinerte.
BMW Intelligent Personal Assistant lansert i sin BMW 3-serie er mye smartere enn vanlige stemmeassistenter. Det kan gjøre det mulig for sjåfører å finne bilrelatert informasjon og betjene bilen ved hjelp av talekommandoer. - Media og underholdning: Også mediebransjen bruker ASR i mange av sine prosjekter. Youtube har lansert en AI-basert assistent som genererer live auto-teksting. Mens du snakker på skjermen, vil assistenten gi undertekstene for å gjøre videoen tilgjengelig for en større gruppe YouTube-brukere.
 Mat industri: Matgiganter som Wendy's og McDonald's er satt til å forbedre sine kundeopplevelser ved å bruke ASR. I mange av deres utsalgssteder har de utplassert fullt funksjonelle ASR-modeller for å ta imot bestillinger, og videresende dem til matlagingsdelen for å gjøre kundebestillingen klar.
Mat industri: Matgiganter som Wendy's og McDonald's er satt til å forbedre sine kundeopplevelser ved å bruke ASR. I mange av deres utsalgssteder har de utplassert fullt funksjonelle ASR-modeller for å ta imot bestillinger, og videresende dem til matlagingsdelen for å gjøre kundebestillingen klar. Telekommunikasjon: Vodafone er en av de største telekomleverandørene i verden. Den har designet sine kundebehandlings- og telefonrelétjenester ved å utnytte ASR-modeller som veileder deg til å løse ulike spørsmål og omdirigere samtalene dine til berørte avdelinger.
Telekommunikasjon: Vodafone er en av de største telekomleverandørene i verden. Den har designet sine kundebehandlings- og telefonrelétjenester ved å utnytte ASR-modeller som veileder deg til å løse ulike spørsmål og omdirigere samtalene dine til berørte avdelinger. Reise og transport: Google Android Auto eller Apple CarPlay har blitt vanlig. De fleste bruker dem til å aktivere navigasjonssystemer, sende meldinger eller bytte musikkspillelister. Men med teknologiske fremskritt blir slike systemer mer raffinerte.
Reise og transport: Google Android Auto eller Apple CarPlay har blitt vanlig. De fleste bruker dem til å aktivere navigasjonssystemer, sende meldinger eller bytte musikkspillelister. Men med teknologiske fremskritt blir slike systemer mer raffinerte. Media og underholdning: Også mediebransjen bruker ASR i mange av sine prosjekter. Youtube har lansert en AI-basert assistent som genererer live auto-teksting. Mens du snakker på skjermen, vil assistenten gi undertekstene for å gjøre videoen tilgjengelig for en større gruppe YouTube-brukere.
Media og underholdning: Også mediebransjen bruker ASR i mange av sine prosjekter. Youtube har lansert en AI-basert assistent som genererer live auto-teksting. Mens du snakker på skjermen, vil assistenten gi undertekstene for å gjøre videoen tilgjengelig for en større gruppe YouTube-brukere.
[Les også: Hva er tale-til-tekst-teknologi og hvordan fungerer det]
Hvordan kan Shaip hjelpe?
Shaip er en av de ledende AI-treningstjenestene som har ekspertise innen flere områder innen AI og ML. De kan hjelpe deg med å bygge ditt eget datasett som kan brukes til forskjellige applikasjoner og prosjekter.
Noen av tjenestene levert av Shaip er:
- Automatisert talegjenkjenning (ASR)
- Skriftlig talesamling
- Transcreation
- Spontane talesamling
- Ytringssamling/ Wake-up Words,
- Tekst-til-tale (TTS)
Du kan benytte deg av disse tjenestene for å få de beste resultatene for dine AI-baserte prosjekter. Finn ut mer om disse tjenestene ved å kontakte ekspertteamet vårt i dag!


