Kunstig intelligens revolusjonerer musikkindustrien, og tilbyr automatiserte komposisjons-, mastering- og fremføringsverktøy. AI-algoritmer genererer nye komposisjoner, forutsier treff og tilpasser lytteropplevelsen, og transformerer musikkproduksjon, distribusjon og forbruk. Denne nye teknologien gir både spennende muligheter og utfordrende etiske dilemmaer.
Maskinlæringsmodeller (ML) krever treningsdata for å fungere effektivt, ettersom en komponist trenger musikknoter for å skrive en symfoni. I musikkverdenen, hvor melodi, rytme og følelser flettes sammen, kan ikke viktigheten av treningsdata av høy kvalitet overvurderes. Det er ryggraden i å utvikle robuste og nøyaktige musikk-ML-modeller for prediktiv analyse, sjangerklassifisering eller automatisk transkripsjon.
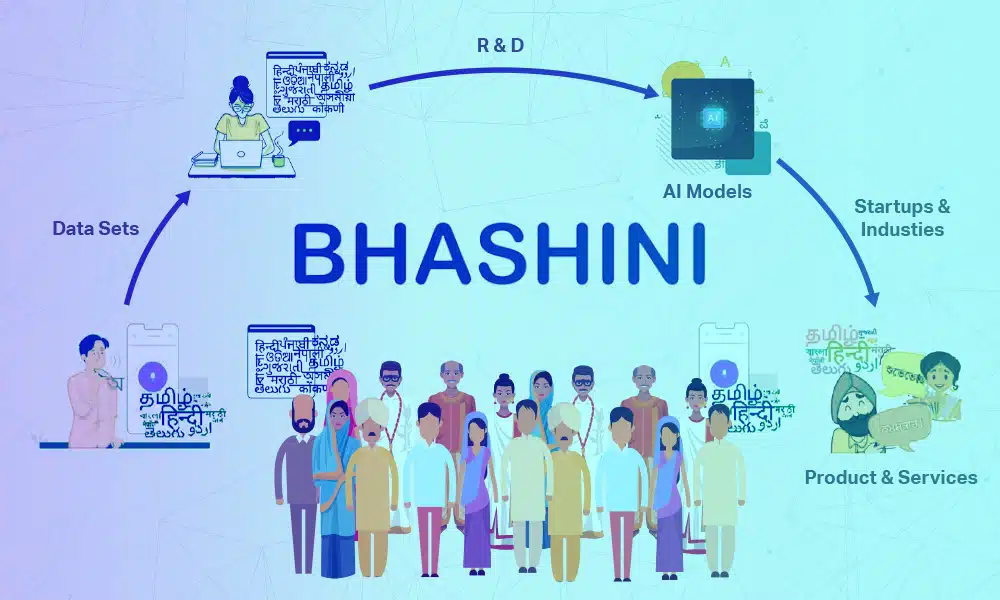
Data, livsnerven til ML-modeller
Maskinlæring er i seg selv datadrevet. Disse beregningsmodellene lærer mønstre fra dataene, slik at de kan foreta spådommer eller beslutninger. For musikk ML-modeller kommer treningsdata ofte i digitaliserte musikkspor, tekster, metadata eller en kombinasjon av disse elementene. Disse dataenes kvalitet, kvantitet og mangfold påvirker modellens effektivitet betydelig.

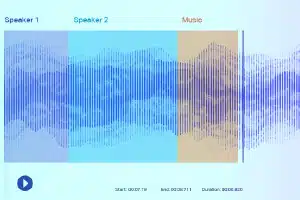
Lydmerking
Med lydmerking får dataannotatorene et opptak og må skille alle de nødvendige lydene og merke dem. Dette kan for eksempel være bestemte nøkkelord eller lyden til et spesifikt musikkinstrument.

Musikkklassifisering
Dataannotatorer kan merke sjangere eller instrumenter i denne typen lydkommentarer. Musikkklassifisering er veldig nyttig for å organisere musikkbiblioteker og forbedre brukeranbefalinger.

Fonetisk nivåsegmentering
Merking og klassifisering av fonetiske segmenter på bølgeformene og spektrogrammene til opptak av individer som synger acapella.
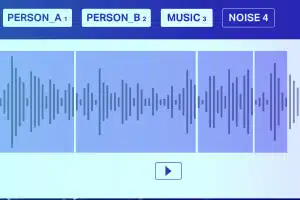
Lydklassifisering
Bortsett fra stillhet/hvit støy, består en lydfil vanligvis av følgende lydtyper Tale, Babble, Musikk og Støy. Kommenter musikknoter nøyaktig for høyere nøyaktighet.
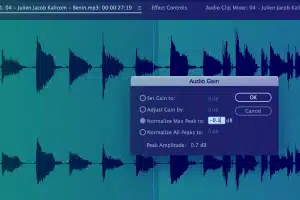
Innhenting av metadatainformasjon
Ta opp viktig informasjon som starttid, sluttid, segment-ID, lydstyrkenivå, primær lydtype, språkkode, høyttaler-ID og andre transkripsjonskonvensjoner, etc.